
我本身刷了大概 600 道左右的题目,总结 200 多篇的题解,另外总结了十多个常见的算法专题,基本已经覆盖了大多数的常见考点和题型,全部放在我的 Github https://github.com/azl397985856/leetcode 。
然而作为一个新手,看着茫茫多的题解和资料难免会陷入一种“不知从何开始”的境地。不必担心,你不是一个人。
实际上,我最近一直在思考“初学者如何快速提高自己的算法能力,高效刷题”。因此我也一直在不断定位自己,最终我对自己作出了定位“用清晰直白的语言还原解题全过程,做西湖区最好的算法题解”。
然而我意识到,我进去了一个很大的误区。我的想法一直是“努力帮助算法小白提高算法能力,高效刷题”。然而算法小白除了清晰直白的算法题解外,还需要系统的前置知识。因此我的假设“大家都会基础的数据结构和算法”很可能就是不成立的。
小白阶段划分
如果让我对算法小白进行一个阶段划分的话,我会将其分为:
阶段一 系统学习数据结构和算法知识。
第一,你不能根本不懂得基础,比如根本不知道什么哈希表,或者只知道其简单的 API。
第二,你不能从网上不断搜索知识,因为这些知识是零散的,不利于新手形成自己的算法观。
当你成功跨越了上面两个坎,那么恭喜你,你可以进入下一个阶段啦。
对于这个阶段,想要跨过。需要系统性学习一些基础知识,推荐啃《算法 4》或者直接啃各个大学里面的教材。实在有困难的,可以先啃《算法图解》,《我的第一本算法书》这种入个门,然后再去啃。
阶段二 针对性刷题。
比如按照力扣的标签去刷。因此上面的学习阶段并不见得你要学习完所有的基础再去刷,而是学习一个专题就可以针对性地刷。比如我学了二分法,就可以找一个二分法的题目刷一下。
想要跨越这一个坎,除了多做题之外,还有一个就是多看题解,多写题解。当然要看优秀的题解,这个我会在后面提到。
如果你跨越完上面两个坎,那么恭喜你, 你已经不是算法小白了(至少对于非算法岗来说)。
我的算法观
继续回到刚才的问题“我的定位误区”。正因为很多小白没有跨越阶段一,因此我的所谓的“用清晰直白的语言还原解题全过程,做西湖区最好的算法题解”对他们没有实质帮助。他们迫切需要的是一个系统地整理算法思想,套路 的东西。因此我准备搞 91,这个就是后话,不再这里赘述。
注意,上面我提到了一个名次算法观。我并不知道这个词是否真的存在,不过这并不重要。如果不存在我就赋予其含义,如果存在我就来重新定义它。
算法观指的是你对于算法全面的认识。比如我拿到一个题目,如何审题,如何抽象成算法模型,如何根据模型选取合适的数据结构和算法。这就需要你对各种数据结构与算法的特性,使用场景有着身后的理解。
我举一个例子,这个例子就是今天(2020-06-12)我的 91 群的每日一题。

API 示例:
1 | class LRUCache: |
按照上面的过程,我们来套一个。
- 如何审题
看完题的话,只要抓住一个核心点即可。对于本题,核心点在于 删除最久未使用,O(1)时间。
- 抽象算法模型
这个题目是一个设计题。API 帮我们设计好了,只需要填充功能即可,也就是说算法模型不需要我们抽象了。
- 根据模型选取合适的数据结构和算法
我们的算法有两个操作:get 和 put。既然要支持这两个操作,肯定要有一个地方存数据。那么我们存到哪里呢?数组?链表?哈希表?其中链表又有很多,单向双向,循环不循环。
由于第一步审题过程中,我们获取到 O(1)时间 这个关键信息。那么:
- 数组无法做到更新,删除 $O(1)$
- 链表无法做到查找,更新,删除 $O(1)$。
有的人说链表更新,删除是 $O(1)$,那么我要问你如何找到需要删除的节点呢?遍历找到的话最坏情况下就是 $O(N)$
- 哈希表是无序的,因此不能实现 删除最久未使用。
似乎单独使用三种的任何一种都是不可以的。那么我们考虑组合多种数据结构。
我刚才说了链表只所以删除和更新都是 $O(N)$,是因为查找的时间损耗。
具体来说,我要删除图中值为 3 的节点,需要移动一次。因为我只能从头开始遍历去找。
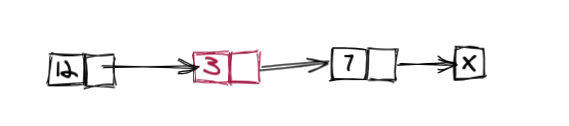
(图 1)
又或者我要更新图中值为 7 的节点,则需要移动两次。

(图 2)
有没有什么办法可以省去这种遍历的时间损耗呢?其实我们的根本目的是找到目标节点, 而找到目标节点最暴力的方式是遍历。有没有巧妙一点的方法呢?毫无疑问,如果不借助额外的空间,这是不可能的。我们的想法只有空间换时间。
假设有这么一种数据结构,你告诉它你想要查的对象,它能帮你在 $O(1)$ 的时间内找到并返回给你结果。结合这个神秘数据结构和链表是不是我们就完成这道题了?这个神秘的数据结构就是哈希表。如果你对哈希表熟悉的话,想到几乎应该是瞬间的事情。如果不熟悉,那么经过排除,也应该可以得出这个结论。相信你随着做题数的增加,这种算法直觉会更加敏锐。
然而上面的空间复杂度是 $O(N)$。如果我的内存有限,不能承受 $O(N)$ 的空间,怎么办呢?相应地,我们可能就需要牺牲时间。那么问题是我们必须要退化到 $O(N)$ 么?显然不是,我们可以搞一些存档点。比如:

这样,我们需要操作 1 前面的,我们就从头开始遍历,如果需要操作 1 后面的,就从 1 开始遍历。时间复杂度最坏的情况可以降低到 $O(N / 2)$。通过进一步增加存档点,可以进一步减少时间,但是会增加空间。这是一种取舍。类似的取舍在实际工程中很多,这里不展开。 如果你了解过跳表, 实际上,上面的算法就是跳表的基本思想。
如果对每一道题你都能按照上面的流程走一遍,并且基于增加适当扩展,我相信你的刷题效率会高得可怕。
每道题都想这么多么?
强烈建议新手都按照上面的逻辑进行思考,做题,并写题解总结。这样随着做题数的增加,量变引起质变,你会发现上面的几个步骤做下来很可能就是几秒钟的事情。如果你擅长图解,或者你经常看别人的图解(比如我的),那么这种图解能够帮你更快地检索大脑中的信息,这个时间会更短。
图解就是大脑检索信息的哈希表?哈哈,Maybe。
题解的水很深
我看了很多人的题解直接就是两句话,然后跟上代码:
1 | class Solution: |
这种题解说实话,只针对那些”自己会, 然后去题解区看看有没有新的更好的解法的人“。但是大多数看题解的人是那种自己没思路,不会做的人。那么这种题解就没什么用了。
我认为好的题解应该是新手友好的,并且能够将解题人思路完整展现的题解。比如看到这个题目,我首先想到了什么(对错没有关系),然后头脑中经过怎么样的筛选将算法筛选到具体某一个或某几个。我的最终算法是如何想到的,有没有一些先行知识。
当然我也承认自己有很多题解也是直接给的答案,这对很多人来说用处不大,甚至有可能有反作用,给他们一种”我已经会了“的假象。实际上他们根本不懂解题人本身原本的想法, 也许是写题解的人觉得”这很自然“,也可能”只是为了秀技“。
刷题顺序
最后给小白一个刷题顺序,帮助大家最大化利用自己的时间。
基础篇(30 天)
基础永远是最重要的,先把最最基础的这些搞熟,磨刀不误砍柴工。
- 数组,队列,栈
- 链表
- 树与递归
- 哈希表
- 双指针
思想篇(30 天)
这些思想是投资回报率极高的,强烈推荐每一个小的专题花一定的时间掌握。
- 二分
- 滑动窗口
- 搜索(BFS,DFS,回溯)
- 动态规划
提高篇(31 天)
这部分收益没那么明显,并且往往需要一定的技术积累。出现的频率相对而言比较低。但是有的题目需要你使用这些技巧。又或者可以使用这些技巧可以实现降维打击。
- 贪心
- 分治
- 位运算
- KMP & RK
- 并查集
- 前缀树
- 线段树
- 堆
最后
目前,我本人也在写一本题解方面的书包括近期组织的 91 算法 ,其目标受众正是“阶段一到阶段二”。为了真正帮助刷题小白成长,我打算画三个月的时间对数据结构和算法进行系统总结,帮助大家跨过阶段一。当然我还会不断更新题解,通过清晰直白的方式来让大家跨越阶段二。
大家也可以关注我的公众号《力扣加加》获取更多更新鲜的 LeetCode 题解
