
前一段时间我分享了几篇关于《数据结构与算法在前端领域的应用》的文章。
文章链接:
这一次我们顺着前面的内容,讲一些经典的数据结构与算法,本期我们来讲一下时下比较火热的React fiber。
这部分内容相对比较硬核和难以消化,否则 React 团队也不会花费两年的时间来搞这一个东西。建议大家多读几遍。
fiber - 一个用于增量更新的数据结构
前面我的文章提到过 fiber 是一种数据结构,并且是一种链式的数据结构。
fiber 是为了下一代调和引擎而引入的一种新的数据结构,而下一代调和引擎最核心的部分就是
“增量渲染”。为了明白这个“增量渲染”,我们需要打一点小小的基础。
分片执行
为了做到上面我提到的“增量渲染”,我们首先要能够停下来。
之前 React 的更新 UI 的策略是自顶向下进行渲染,如果没有人工的干涉,React 实际上会更新到
所有的子组件,这在大多数情况下没有问题。
然而随着项目越来越复杂,这种弊端就非常明显了。单纯看这一点,Vue 在这方面做的更好,
Vue 提供了更加细粒度的更新组件的方式,甚至无需用户参与。 这是两者设计理念上的差异,不关乎
好坏,只是适用场景不一样罢了。
值得一提的是,Vue 的这种细粒度监听和更新的方式,实际上是内存层面和计算层面的权衡。
社区中一些新的优秀框架,也借鉴了 Vue 的这种模式,并且完成了进一步的进化,对不同的类型进行划分,
并采取不同的监听更新策略,实际上是一种更加“智能“的取舍罢了。
言归正传,我们如何才能做到”增量更新“呢?
- 首先你要能够在进行到中途的时候停下来
- 你能够继续刚才的工作,换句话说可以重用之前的计算结果
实现这两点靠的正是我们今天的主角 fiber,稍后我们再讲。
比如之前 React 执行了一个 100ms 的更新过程,对于新的调和算法,
会将这个过程划分为多个过程,当然每一份时间很可能是不同的。
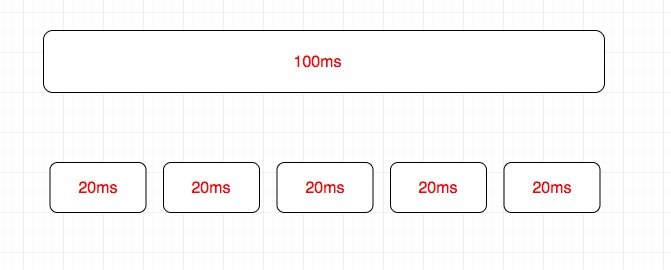
由于总时间不会减少,我们设置还增加了调度(上面我提到的两条)的代码,
因此单纯从总时间上,甚至是一种倒退。但是为什么用户会感觉到更快了呢?
这就是下面我们要讲的调度器。
三大核心组件 - Scheduler, Reconciliation, Renderer
事实上, React 核心的算法包含了三个核心部分,分别是Scheduler,, Reconciliation,Renderer。
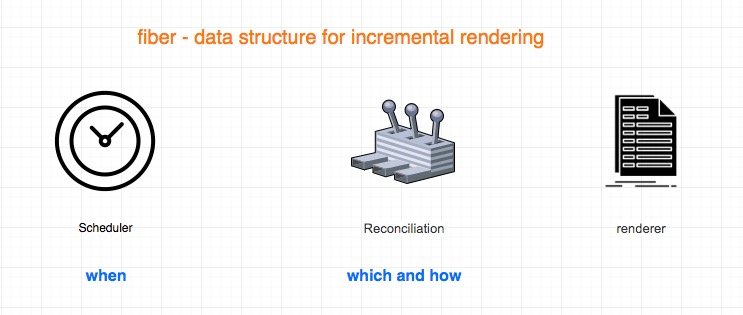
- scheduler 用于决定何时去执行。
前面提到了,整个更新过程要比之前的做法要长。总时间变长的情况下,用户感觉性能更好的原因在于
scheduler。 对于用户而言,界面交互,动画,界面更新的优先级实际上是不一样的。
通过保证高优先级的事件的执行,比如用户输入,动画。 可以让用户有性能很好的感觉。
做到这一点实际上原理很简单,即使前面提到的 chunks,再加上我们给每一个任务分配一个优先级,
从而保证 chunks 的执行顺序中高优先级的在前面。
浏览器实际上自己也会对一些事件区分优先级。
- Reconciliation 决定哪部分需要更新,以及如何“相对最小化”完成更新过程。
这部分算法主要上衣基于VDOM这种数据结构来完成的。
这部分的算法实际上就是一个“阉割版的最小编辑树算法”。

- renderer 使用 Reconciliation 的计算结果,然后将这部分差异,最小化更新到视图。可以是 DOM,也可以是
native, 理论上可以是任何一种渲染容器。
在 DOM 中,这部分的工作由 React-DOM 来完成。它会生成一些 DOM 操作的 API,从而去完成一些副作用,
这里指的是更新 DOM。
fiber - 一个虚拟调用栈
实际上,fiber 做的事情就是将之前 react 更新策略进行了重构。
之前的更新策略是从顶向下,通过调用栈的形式保存已经更新的信息。
这本身没有问题, 但是这和我们刚才想要实现的效果是不匹配的,我们需要 chunks 的效果。
而之前的策略是从顶到下一口气执行完,不断 push stack,然后 pop stack,直到 stack 为空。
fiber 正是模拟了调用栈,并且通过链表来重新组织,一方面使得我们可以实现 chunks 的功能。
另一方面可以和 VDOM 进行很好的对应和映射。
v = f(d)
这是我从 React 官方介绍 fiber 的一个地方抄来的公式。
它想表达的是 react 是一个视图管理框架,并且是数据驱动的,唯一的数据会驱动产生唯一的视图。
我们可以把每一个组件都看成一个 view,然而我们的工作就是计算所有的组件的最新的 view。
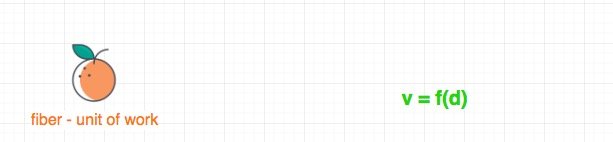
那么 fiber 是如何完成“增量更新”呢? 秘诀就是它相当于“重新实现了浏览器调用栈”。
我们来看一下,fiber 是如何实现传统调用栈的功能的。
fiber 和 传统调用栈的区别
传统的调用栈,我们实际上将生成 view 的工作放到栈里面执行,浏览器的栈有一个特点就是
“你给它一个任务,它必须一口气执行完”。
而 fiber 由于是自己设计的,因此可以没有这个限制。 具体来说,两者的对应关系如下:
1 | 传统调用栈 fiber |
用图来表示的话,大概是这样:
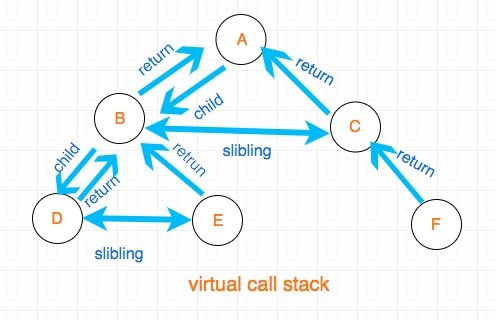
其中具体的算法,我预计会在我的从零开始开发一个 React 中更新。
总结
本篇文章介绍了fiber,fiber其实是一种用于增量更新的数据结构。
是为了下一代调和引擎而引入的一种新的数据结构,而下一代调和引擎最核心的部分就是
“增量渲染”。
我们介绍了几个基本概念和组件,包括分片执行, react三大核心组件 - Scheduler, Reconciliation, Renderer。
最后我们说了“fiber实际上就是一个虚拟调用栈”,并结合传统调用栈的特点和弊端,讲解了fiber是如何组织,
从而改进了传统调用栈带来的问题的。