
作者: 阿吉
校对&整理: lucifer
当下浏览器内核主要有 Webkit、Blink 等。本文分析注意是自 2001 年 Webkit 从 KHTML 分离出去并开源后,各大浏览器厂商魔改 Webkit 的时期,这些魔改的内核最终以 Chromium 受众最多而脱颖而出。本文就以 Chromium 浏览器架构为基础,逐层探入进行剖析。
引子
这里以一个面试中最常见的题目从 URL 输入到浏览器渲染页面发生了什么?开始。
这个很常见的题目,涉及的知识非常广泛。大家可先从浏览器监听用户输入开始,浏览器解析 url 的部分,分析出应用层协议 是 HTTPS 还是 HTTP 来决定是否经过会话层 TLS 套接字,然后到 DNS 解析获取 IP,建立 TCP 套接字池 以及 TCP 三次握手,数据封装切片的过程,浏览器发送请求获取对应数据,如何解析 HTML,四次挥手等等等等。 这个回答理论上可以非常详细,远比我提到的多得多。
本文试图从浏览器获取资源开始探究 Webkit。如浏览器如何获取资源,获取资源时 Webkit 调用了哪些资源加载器(不同的资源使用不同的加载器),Webkit 如何解析 HTML 等入手。想要从前端工程师的角度弄明白这些问题,可以先暂时抛开 C++源码,从浏览器架构出发,做到大致了解。之后学有余力的同学再去深入研究各个底层细节。
本文的路线循序渐进,从 Chromium 浏览器架构出发,到 Webkit 资源下载时对应的浏览器获取对应资源如 HTML、CSS 等,再到 HTML 的解析,再到 JS 阻塞 DOM 解析而产生的 Webkit 优化 引出浏览器多线程架构,继而出于安全性和稳定性的考虑引出浏览器多进程架构。
一. Chromium 浏览器架构

(Chromium 浏览器架构)
我们通常说的浏览器内核,指的是渲染引擎。
WebCore 基本是共享的,只是在不同浏览器中使用 Webkit 的实现方式不同。它包含解析 HTML 生成 DOM、解析 CSS、渲染布局、资源加载器等等,用于加载和渲染网页。
JS 解析可以使用 JSCore 或 V8 等 JS 引擎。我们熟悉的谷歌浏览器就是使用 V8。比如比较常见的有内置属性 [[scope]] 就仅在 V8 内部使用,用于对象根据其向上索引自身不存在的属性。而对外暴露的 API,如 __proto__ 也可用于更改原型链。实际上 __proto__ 并不是 ES 标准提供的,它是浏览器提供的(浏览器可以不提供,因此如果有浏览器不提供的话这也并不是 b ug)。
Webkit Ports 是不共享的部分。它包含视频、音频、图片解码、硬件加速、网络栈等等,常用于移植。
同时,浏览器是多进程多线程架构,稍后也会细入。
在解析 HTML 文档之前,需要先获取资源,那么资源的获取在 Webkit 中应该如何进行呢?
二.Webkit 资源加载
HTTP 是超文本传输协议,超文本的含义即包含了文本、图片、视频、音频等等。其对应的不同文件格式,在 Webkit 中 需要调用不同的资源加载器,即 特定资源加载器。
而浏览器有四级缓存,Disk Cache 是我们最常说的通过 HTTP Header 去控制的,比如强缓存、协商缓存。同时也有浏览器自带的启发式缓存。而 Webkit 对应使用的加载器是资源缓存机制的资源加载器 CachedResoureLoader 类。
如果每个资源加载器都实现自己的加载方法,则浪费内存空间,同时违背了单一职责的原则,因此可以抽象出一个共享类,即通用资源加载器 ResoureLoader 类。 Webkit 资源加载是使用了三类加载器:特定资源加载器,资源缓存机制的资源加载器 CachedResoureLoader 和 通用资源加载器 ResoureLoader。
既然说到了缓存,那不妨多谈一点。
资源既然缓存了,那是如何命中的呢?答案是根据资源唯一性的特征 URL。资源存储是有一定有效期的,而这个有效期在 Webkit 中采用的就是 LRU 算法。那什么时候更新缓存呢?答案是不同的缓存类型对应不同的缓存策略。我们知道缓存多数是利用 HTTP 协议减少网络负载的,即强缓存、协商缓存。但是如果关闭缓存了呢? 比如 HTTP/1.0 Pragma:no-cache 和 HTTP/1.1 Cache-Control: no-cache。此时,对于 Webkit 来说,它会清空全局唯一的对象 MemoryCache 中的所有资源。
资源加载器内容先到这里。浏览器架构是多进程多线程的,其实多线程可以直接体现在资源加载的过程中,在 JS 阻塞 DOM 解析中发挥作用,下面我们详细讲解一下。
三.浏览器架构
浏览器是多进程多线程架构。
对于浏览器来讲,从网络获取资源是非常耗时的。从资源是否阻塞渲染的角度,对浏览器而言资源仅分为两类:阻塞渲染如 JS 和 不阻塞渲染如图片。
我们都知道 JS 阻塞 DOM 解析,反之亦然。然而对于阻塞,Webkit 不会傻傻等着浪费时间,它在内部做了优化:启动另一个线程,去遍历后续的 HTML 文档,收集需要的资源 URL,并发下载资源。最常见的比如<script async>和<script defer>,其 JS 资源下载和 DOM 解析是并行的,JS 下载并不会阻塞 DOM 解析。这就是浏览器的多线程架构。

总结一下,多线程的好处就是,高响应度,UI 线程不会被耗时操作阻塞而完全阻塞浏览器进程。
关于多线程,有 GUI 渲染线程,负责解析 HTML、CSS、渲染和布局等等,调用 WebCore 的功能。JS 引擎线程,负责解析 JS 脚本,调用 JSCore 或 V8。我们都知道 JS 阻塞 DOM 解析,这是因为 Webkit 设计上 GUI 渲染线程和 JS 引擎线程的执行是互斥的。如果二者不互斥,假设 JS 引擎线程清空了 DOM 树,在 JS 引擎线程清空的过程中 GUI 渲染线程仍继续渲染页面,这就造成了资源的浪费。更严重的,还可能发生各种多线程问题,比如脏数据等。
另外我们常说的 JS 操作 DOM 消耗性能,其实有一部分指的就是 JS 引擎线程和 GUI 渲染线程之间的通信,线程之间比较消耗性能。
除此之外还有别的线程,比如事件触发线程,负责当一个事件被触发时将其添加到待处理队列的队尾。
值得注意的是,多启动的线程,仅仅是收集后续资源的 URL,线程并不会去下载资源。该线程会把下载的资源 URL 送给 Browser 进程,Browser 进程调用网络栈去下载对应的资源,返回资源交由 Renderer 进程进行渲染,Renderer 进程将最终的渲染结果返回 Browser 进程,由 Browser 进程进行最终呈现。这就是浏览器的多进程架构。
多进程加载资源的过程是如何的呢?我们上面说到的 HTML 文档在浏览器的渲染,是交由 Renderer 进程的。Renderer 进程在解析 HTML 的过程中,已搜集到所有的资源 URL,如 link CSS、Img src 等等。但出于安全性和效率的角度考虑,Renderer 进程并不能直接下载资源,它需要通过进程间通信将 URL 交由 Browser 进程,Browser 进程有权限调用 URLRequest 类从网络或本地获取资源。
近年来,对于有的浏览器,网络栈由 Browser 进程中的一个模块,变成一个单独的进程。
同时,多进程的好处远远不止安全这一项,即沙箱模型。还有单个网页或者第三方插件的崩溃,并不会影响到浏览器的稳定性。资源加载完成,对于 Webkit 而言,它需要调用 WebCore 对资源进行解析。那么我们先看下 HTML 的解析。之后我们再谈一下,对于浏览器来说,它拥有哪些进程呢?
四.HTML 解析
对于 Webkit 而言,将解析半结构化的 HTML 生成 DOM,但是对于 CSS 样式表的解析,严格意义 CSSOM 并不是树,而是一个映射表集合。我们可以通过 document.styleSheets 来获取样式表的有序集合来操作 CSSOM。对于 CSS,Webkit 也有对应的优化策略—-ComputedStyle。ComputedStyle 就是如果多个元素的样式可以不经过计算就确认相等,那么就仅会进行一次样式计算,其余元素仅共享该 ComputedStyle。
共享 ComputedStyle 原则:
(1) TagName 和 Class 属性必须一样。
(2)不能有 Style。
(3)不能有 sibling selector。
(4)mappedAttribute 必须相等。
对于 DOM 和 CSSOM,大家说的合成的 render 树在 Webkit 而言是不存在的,在 Webkit 内部生成的是 RenderObject,在它的节点在创建的同时,会根据层次结构创建 RenderLayer 树,同时构建一个虚拟的绘图上下文,生成可视化图像。这四个内部表示结构会一直存在,直到网页被销毁。
RenderLayer 在浏览器控制台中 Layers 功能卡中可以看到当前网页的图层分层。图层涉及到显式和隐式,如 scale()、z-index 等。层的优点之一是只重绘当前层而不影响其他层,这也是 Webkit 做的优化之一。同时 V8 引擎也做了一些优化,比如说隐藏类、优化回退、内联缓存等等。
五.浏览器进程
浏览器进程包括 Browser 进程、Renderer 进程、GPU 进程、NPAPI 插件进程、Pepper 进程等等。下面让我们详细看看各大进程。
Browser 进程:浏览器的主进程,有且仅有一个,它是进程祖先。负责页面的显示和管理、其他进程的管理。
Renderer 进程:网页的渲染进程,可有多个,和网页数量不一定是一一对应关系。它负责网页的渲染,Webkit 的渲染工作就是在这里完成的。
GPU 进程:最多一个。仅当 GPU 硬件加速被打开时创建。它负责 3D 绘制。
NPAPI 进程:为 NPAPI 类型的插件而创建。其创建的基本原则是每种类型的插件都只会被创建一次,仅当使用时被创建,可被共享。
Pepper 进程:同 NPAPI 进程,不同的是 它为 Pepper 插件而创建的进程。
注意:如果页面有 iframe,它会形成影子节点,会运行在单独的进程中。
我们仅仅在围绕 Chromium 浏览器来说上述进程,因为在移动端,毕竟手机厂商很多,各大厂商对浏览器进程的支持也不一样。这其实也是我们最常见的 H5 兼容性问题,比如 IOS margin-bottom 失效等等。再比如 H5 使用 video 标签做直播,也在不同手机之间会存在问题。有的手机直播页面跳出主进程再回来,就会黑屏。
以 Chromium 的 Android 版为例子,不存在 GPU 进程,GPU 进程变成了 Browser 进程的线程。同时,Renderer 进程演变为服务进程,同时被限制了最大数量。
为了方便起见,我们以 PC 端谷歌浏览器为例子,打开任务管理器,查看当前浏览器中打开的网页及其进程。
当前我打开了 14 个网页,不太好容易观察,但可以从下图中看到,只有一个 Browser 进程,即第 1 行。但是打开的网页对应的 Renderer 进程,并不一定是一个网页对应一个 Renderer 进程,这跟 Renderer 进程配置有关系。比如你看第 6、7 行是每个标签页创建独立 Renderer 进程,但是蓝色光标所在的第 8、9、10 行是共用一个 Renderer 进程,这属于为每个页面创建一个 Renderer 进程。因为第 9、10 行打开的页面是从第 8 行点击链接打开的。第 2 行的 GPU 进程也清晰可见,以及第 3、4、5 行的插件进程。
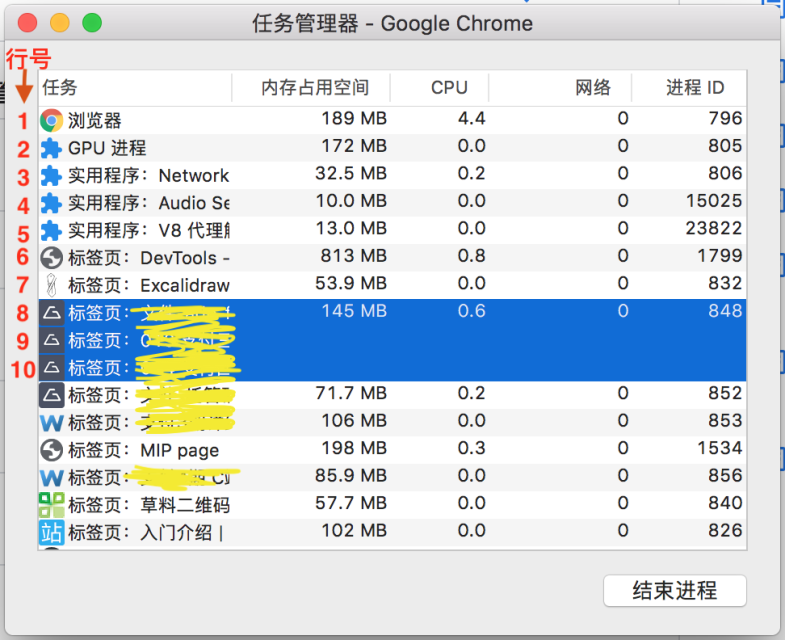
关于,Renderer 进程和打开的网页并不一定是一一对应的关系,下面我们详细说一下 Renderer 进程。当前只有四种多进程策略:
Process-per-site-instance: 为每个页面单独创建一个进程,从某个网站打开的一系列网站都属于同一个进程。这是浏览器的默认项。上图中的蓝色光标就是这种情况。
Process-per-site:同一个域的页面共享一个进程。
Process-per-tab:为每个标签页创建一个独立的进程。比如上图第 6、7 行。
Single process:所有的渲染工作作为多个线程都在 Browser 进程中进行。这个基本不会用到的。
Single process 突然让我联想到零几年的时候,那会 IE 应该还是单进程浏览器。单进程就是指所有的功能模块全部运行在一个进程,就类似于 Single process。那会玩 4399 如果一个网页卡死了,没响应,点关闭等一会,整个浏览器就崩溃了,得重新打开。所以多进程架构是有利于浏览器的稳定性的。虽然当下浏览器架构为多进程架构,但如果 Renderer 进程配置为 Process-per-site-instance,也可能会出现由于单个页面卡死而导致所有页面崩溃的情况。
故浏览器多进程架构综上所述,好处有三:
(1)单个网页的崩溃不会影响这个浏览器的稳定性。
(2)第三方插件的崩溃不会影响浏览器的稳定性。
(3)沙箱模型提供了安全保障。
总结
Webkit 使用三类资源加载器去下载对应的资源,并存入缓存池中,对于 HTML 文档的解析,在阻塞时调用另一个线程去收集后续资源的 URL,将其发送给 Browser 进程,Browser 进程调用网络栈去下载对应的本地或网络资源,返回给 Renderer 进程进行渲染,Renderer 进程将最终渲染结果(一系列的合成帧)发送给 Browser 进程,Browser 进程将这些合成帧发送给 GPU 从而显示在屏幕上。
(文中有部分不严谨的地方,已由 lucifer 指出修改)