
本文是我的 91 算法第一期的部分讲义内容。 91 算法第一期已经接近尾声,二期的具体时间关注我的公众号即可,一旦开放,会第一时间在公众号《力扣加加》通知大家。
动态规划可以理解为是查表的递归(记忆化)。那么什么是递归?什么是查表(记忆化)?
递归
定义: 递归是指在函数的定义中使用函数自身的方法。
算法中使用递归可以很简单地完成一些用循环实现的功能,比如二叉树的左中右序遍历。递归在算法中有非常广泛的使用,包括现在日趋流行的函数式编程。
纯粹的函数式编程中没有循环,只有递归。
有意义的递归算法会把问题分解成规模缩小的同类子问题,当子问题缩写到寻常的时候,我们可以知道它的解。然后我们建立递归函数之间的联系即可解决原问题,这也是我们使用递归的意义。准确来说, 递归并不是算法,它是和迭代对应的一种编程方法。只不过,我们通常借助递归去分解问题而已。
一个问题要使用递归来解决必须有递归终止条件(算法的有穷性),也就是顺递归会逐步缩小规模到寻常。
虽然以下代码也是递归,但由于其无法结束,因此不是一个有效的算法:
1 | def f(n): |
更多的情况应该是:
1 | def f(n): |
练习递归
一个简单练习递归的方式是将你写的迭代全部改成递归形式。比如你写了一个程序,功能是“将一个字符串逆序输出”,那么使用迭代将其写出来会非常容易,那么你是否可以使用递归写出来呢?通过这样的练习,可以让你逐步适应使用递归来写程序。
如果你已经对递归比较熟悉了,那么我们继续往下看。
递归中的重复计算
递归中可能存在这么多的重复计算,为了消除这种重复计算,一种简单的方式就是记忆化递归。即一边递归一边使用“记录表”(比如哈希表或者数组)记录我们已经计算过的情况,当下次再次碰到的时候,如果之前已经计算了,那么直接返回即可,这样就避免了重复计算。而动态规划中 DP 数组其实和这里“记录表”的作用是一样的。
递归的时间复杂度分析
敬请期待我的新书。
小结
使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。这里我列举了几道算法题目,这几道算法题目都可以用递归轻松写出来:
递归实现 sum
二叉树的遍历
走楼梯问题
汉诺塔问题
杨辉三角
当你已经适应了递归的时候,那就让我们继续学习动态规划吧!
动态规划
如果你已经熟悉了递归的技巧,那么使用递归解决问题非常符合人的直觉,代码写起来也比较简单。这个时候我们来关注另一个问题 - 重复计算 。我们可以通过分析(可以尝试画一个递归树),可以看出递归在缩小问题规模的同时是否可能会重复计算。 279.perfect-squares 中 我通过递归的方式来解决这个问题,同时内部维护了一个缓存来存储计算过的运算,这么做可以减少很多运算。 这其实和动态规划有着异曲同工的地方。
小提示:如果你发现并没有重复计算,那么就没有必要用记忆化递归或者动态规划了。
因此动态规划就是枚举所以可能。不过相比暴力枚举,动态规划不会有重复计算。因此如何保证枚举时不重不漏是关键点之一。 递归由于使用了函数调用栈来存储数据,因此如果栈变得很大,那么会容易爆栈。
爆栈
我们结合求和问题来讲解一下,题目是给定一个数组,求出数组中所有项的和,要求使用递归实现。
代码:
1 | function sum(nums) { |
我们用递归树来直观地看一下。
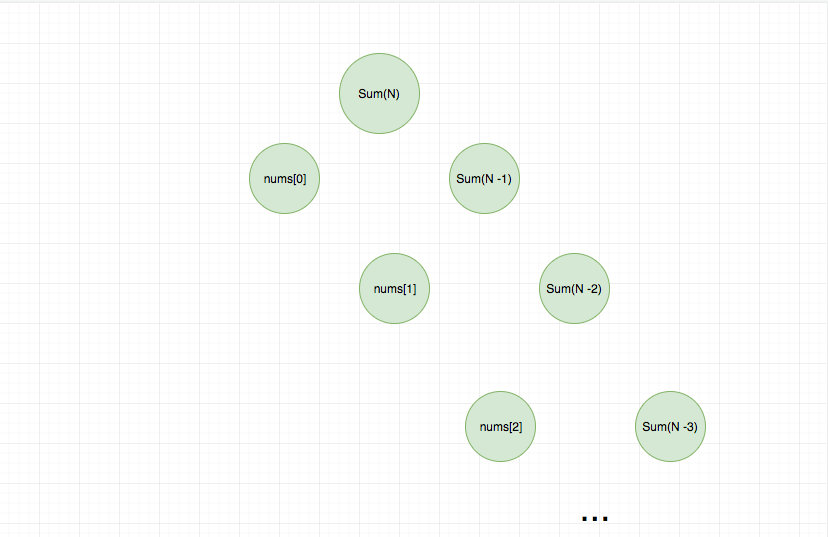
这种做法本身没有问题,但是每次执行一个函数都有一定的开销,拿 JS 引擎执行 JS 来说,每次函数执行都会进行入栈操作,并进行预处理和执行过程,所以内存会有额外的开销,数据量大的时候很容易造成爆栈。
浏览器中的 JS 引擎对于代码执行栈的长度是有限制的,超过会爆栈,抛出异常。
重复计算
我们再举一个重复计算的例子,问题描述:
一个人爬楼梯,每次只能爬 1 个或 2 个台阶,假设有 n 个台阶,那么这个人有多少种不同的爬楼梯方法?
由于上第 n 级台阶一定是从 n - 1 或者 n - 2 来的,因此 上第 n 级台阶的数目就是 上 n - 1 级台阶的数目加上 n - 1 级台阶的数目。
递归代码:
1 | function climbStairs(n) { |
我们继续用一个递归树来直观感受以下:
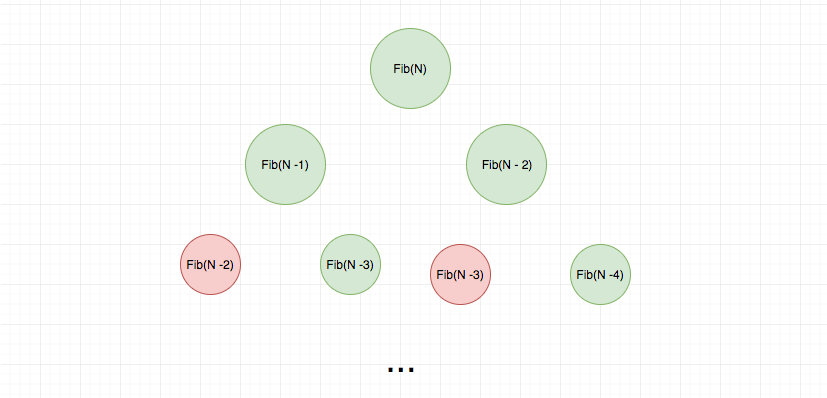
红色表示重复的计算
可以看出这里面有很多重复计算,我们可以使用一个 hashtable 去缓存中间计算结果,从而省去不必要的计算。
那么动态规划是怎么解决这个问题呢? 答案也是“查表”,不过区别于递归使用函数调用栈,动态规划通常使用的是 dp 数组,数组的索引通常是问题规模,值通常是递归函数的返回值。递归是从问题的结果倒推,直到问题的规模缩小到寻常。 动态规划是从寻常入手, 逐步扩大规模到最优子结构。
如果上面的爬楼梯问题,使用动态规划,代码是这样的:
1 | function climbStairs(n) { |
不会也没关系,我们将递归的代码稍微改造一下。其实就是将函数的名字改一下:
1 | function dp(n) { |
dp[n] 和 dp(n) 对比看,这样是不是有点理解了呢? 只不过递归用调用栈枚举状态, 而动态规划使用迭代枚举状态。
动态规划的查表过程如果画成图,就是这样的:
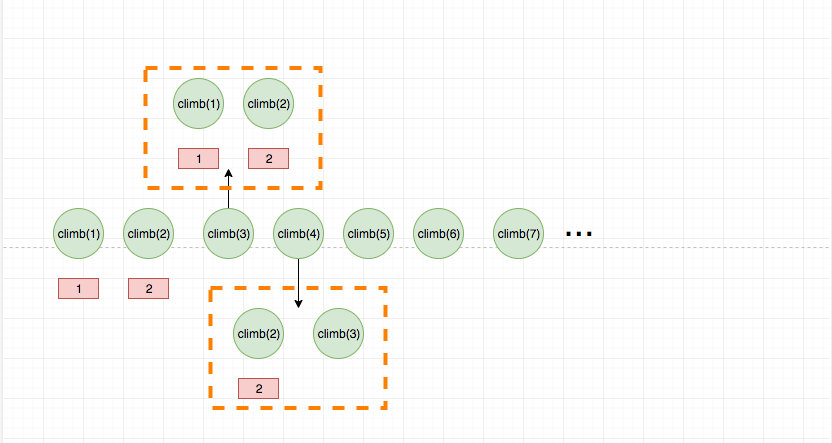
虚线代表的是查表过程
这道题目是动态规划中最简单的问题了,因为设计到单个因素的变化,如果涉及到多个因素,就比较复杂了,比如著名的背包问题,挖金矿问题等。
对于单个因素的,我们最多只需要一个一维数组即可,对于如背包问题我们需要二维数组等更高纬度。
爬楼梯我们并没有必要使用一维数组,而是借助两个变量来实现的,空间复杂度是 O(1)。代码:
1 | function climbStairs(n) { |
之所以能这么做,是因为爬楼梯问题的状态转移方程中当前状态只和前两个状态有关,因此只需要存储这两个即可。 动态规划问题有很多这种讨巧的方式,这个技巧叫做滚动数组。
再次强调一下:
- 如果说递归是从问题的结果倒推,直到问题的规模缩小到寻常。 那么动态规划就是从寻常入手, 逐步扩大规模到最优子结构。
- 记忆化递归和动态规划没有本质不同。都是枚举状态,并根据状态直接的联系逐步推导求解。
- 动态规划性能通常更好。 一方面是递归的栈开销,一方面是滚动数组的技巧。
动态规划的三个要素
状态转移方程
临界条件
枚举状态
可以看出,用递归解决也是一样的思路
在上面讲解的爬楼梯问题中,如果我们用 f(n) 表示爬 n 级台阶有多少种方法的话,那么:
1 | f(1) 与 f(2) 就是【边界】 |
我用动态规划的形式表示一下:
1 | dp[0] 与 dp[1] 就是【边界】 |
可以看出两者是多么的相似。
实际上临界条件相对简单,大家只有多刷几道题,里面就有感觉。困难的是找到状态转移方程和枚举状态。这两个核心点的都建立在已经抽象好了状态的基础上。比如爬楼梯的问题,如果我们用 f(n) 表示爬 n 级台阶有多少种方法的话,那么 f(1), f(2), … 就是各个独立的状态。
不过状态的定义都有特点的套路。 比如一个字符串的状态,通常是 dp[i] 表示字符串 s 以 i 结尾的 ….。 比如两个字符串的状态,通常是 dp[i][j] 表示字符串 s1 以 i 结尾,s2 以 j 结尾的 ….。
当然状态转移方程可能不止一个, 不同的转移方程对应的效率也可能大相径庭,这个就是比较玄学的话题了,需要大家在做题的过程中领悟。
搞定了状态的定义,那么我们来看下状态转移方程。
状态转移方程
爬楼梯问题由于上第 n 级台阶一定是从 n - 1 或者 n - 2 来的,因此 上第 n 级台阶的数目就是 上 n - 1 级台阶的数目加上 n - 1 级台阶的数目。
上面的这个理解是核心, 它就是我们的状态转移方程,用代码表示就是 f(n) = f(n - 1) + f(n - 2)。
实际操作的过程,有可能题目和爬楼梯一样直观,我们不难想到。也可能隐藏很深或者维度过高。 如果你实在想不到,可以尝试画图打开思路,这也是我刚学习动态规划时候的方法。当你做题量上去了,你的题感就会来,那个时候就可以不用画图了。
状态转移方程实在是没有什么灵丹妙药,不同的题目有不同的解法。状态转移方程同时也是解决动态规划问题中最最困难和关键的点,大家一定要多多练习,提高题感。接下来,我们来看下不那么困难,但是新手疑问比较多的问题 - 如何枚举状态。
如何枚举状态
前面说了如何枚举状态,才能不重不漏是枚举状态的关键所在。
- 如果是一维状态,那么我们使用一层循环可以搞定。
- 如果是两维状态,那么我们使用两层循环可以搞定。
- 。。。
这样可以保证不重不漏。
但是实际操作的过程有很多细节比如:
- 一维状态我是先枚举左边的还是右边的?(从左到右遍历还是从右到左遍历)
- 二维状态我是先枚举左上边的还是右上的,还是左下的还是右下的?
- 里层循环和外层循环的位置关系(可以互换么)
- 。。。
其实这个东西和很多因素有关,很难总结出一个规律,而且我认为也完全没有必要去总结规律。不过这里我还是总结了一个关键点,那就是:
- 如果你没有使用滚动数组的技巧,那么遍历顺序取决于状态转移方程。比如:
1 | for i in range(1, n + 1): |
那么我们就需要从左到右遍历,原因很简单,因为 dp[i] 依赖于 dp[i - 1],因此计算 dp[i] 的时候, dp[i - 1] 需要已经计算好了。
二维的也是一样的,大家可以试试。
- 如果你使用了滚动数组的技巧,则怎么遍历都可以,但是不同的遍历意义通常不不同的。比如我将二维的压缩到了一维:
1 | for i in range(1, n + 1): |
这样是可以的。 dp[j - 1] 实际上指的是压缩前的 dp[i][j - 1]
而:
1 | for i in range(1, n + 1): |
这样也是可以的。 但是 dp[j - 1] 实际上指的是压缩前的 dp[i - 1][j - 1]。因此实际中采用怎么样的遍历手段取决于题目。我特意写了一个 【完全背包问题】套路题(1449. 数位成本和为目标值的最大数字 文章,通过一个具体的例子告诉大家不同的遍历有什么实际不同,强烈建议大家看看,并顺手给个三连。
- 关于里外循环的问题,其实和上面原理类似。
这个比较微妙,大家可以参考这篇文章理解一下 0518.coin-change-2。
小结
关于如何确定临界条件通常是比较简单的,多做几个题就可以快速掌握。
关于如何确定状态转移方程,这个其实比较困难。 不过所幸的是,这些套路性比较强, 比如一个字符串的状态,通常是 dp[i] 表示字符串 s 以 i 结尾的 ….。 比如两个字符串的状态,通常是 dp[i][j] 表示字符串 s1 以 i 结尾,s2 以 j 结尾的 ….。 这样遇到新的题目可以往上套, 实在套不出那就先老实画图,不断观察,提高题感。
关于如何枚举状态,如果没有滚动数组, 那么根据转移方程决定如何枚举即可。 如果用了滚动数组,那么要注意压缩后和压缩前的 dp 对应关系即可。
动态规划为什么要画表格
动态规划问题要画表格,但是有的人不知道为什么要画,就觉得这个是必然的,必要要画表格才是动态规划。
其实动态规划本质上是将大问题转化为小问题,然后大问题的解是和小问题有关联的,换句话说大问题可以由小问题进行计算得到。这一点是和用递归解决一样的, 但是动态规划是一种类似查表的方法来缩短时间复杂度和空间复杂度。
画表格的目的就是去不断推导,完成状态转移, 表格中的每一个 cell 都是一个小问题, 我们填表的过程其实就是在解决问题的过程,
我们先解决规模为寻常的情况,然后根据这个结果逐步推导,通常情况下,表格的右下角是问题的最大的规模,也就是我们想要求解的规模。
比如我们用动态规划解决背包问题, 其实就是在不断根据之前的小问题A[i - 1][j] A[i -1][w - wj]来询问:
- 应该选择它
- 还是不选择它
至于判断的标准很简单,就是价值最大,因此我们要做的就是对于选择和不选择两种情况分别求价值,然后取最大,最后更新 cell 即可。
其实大部分的动态规划问题套路都是“选择”或者“不选择”,也就是说是一种“选择题”。 并且大多数动态规划题目还伴随着空间的优化(滚动数组),这是动态规划相对于传统的记忆化递归优势的地方。除了这点优势,就是上文提到的使用动态规划可以减少递归产生的函数调用栈,因此性能上更好。
相关问题
- 0091.decode-ways
- 0139.word-break
- 0198.house-robber
- 0309.best-time-to-buy-and-sell-stock-with-cooldown
- 0322.coin-change
- 0416.partition-equal-subset-sum
- 0518.coin-change-2
总结
本篇文章总结了算法中比较常用的两个方法 - 递归和动态规划。递归的话可以拿树的题目练手,动态规划的话则将我上面推荐的刷完,再考虑去刷力扣的动态规划标签即可。
大家前期学习动态规划的时候,可以先尝试使用记忆化递归解决。然后将其改造为动态规划,这样多练习几次就会有感觉。之后大家可以练习一下滚动数组,这个技巧很有用,并且相对来说比较简单。 比较动态规划的难点在于枚举所以状态(无重复) 和 寻找状态转移方程。
如果你只能记住一句话,那么请记住:递归是从问题的结果倒推,直到问题的规模缩小到寻常。 动态规划是从寻常入手, 逐步扩大规模到最优子结构。
另外,大家可以去 LeetCode 探索中的 递归 I 中进行互动式学习。