
本文是前缀和专题第一篇。系列目录如下:
- 一维前缀和(本文)
- 二维前缀和
我花了几天时间,从力扣中精选了五道相同思想的题目,来帮助大家解套,如果觉得文章对你有用,记得点赞分享,让我看到你的认可,有动力继续做下去。
- 467. 环绕字符串中唯一的子字符串(中等)
- 795. 区间子数组个数(中等)
- 904. 水果成篮(中等)
- 992. K 个不同整数的子数组(困难)
- 1109. 航班预订统计(中等)
前四道题都是滑动窗口的子类型,我们知道滑动窗口适合在题目要求连续的情况下使用, 而前缀和也是如此。二者在连续问题中,对于优化时间复杂度有着很重要的意义。 因此如果一道题你可以用暴力解决出来,而且题目恰好有连续的限制, 那么滑动窗口和前缀和等技巧就应该被想到。
除了这几道题, 还有很多题目都是类似的套路, 大家可以在学习过程中进行体会。今天我们就来一起学习一下。
前菜
我们从一个简单的问题入手,识别一下这种题的基本形式和套路,为之后的四道题打基础。当你了解了这个套路之后, 之后做这种题就可以直接套。
需要注意的是这四道题的前置知识都是 滑动窗口, 不熟悉的同学可以先看下我之前写的 滑动窗口专题(思路 + 模板)
母题 0
有 N 个的正整数放到数组 A 里,现在要求一个新的数组 B,新数组的第 i 个数 B[i]是原数组 A 第 0 到第 i 个数的和。
这道题可以使用前缀和来解决。 前缀和是一种重要的预处理,能大大降低查询的时间复杂度。我们可以简单理解前缀和为“数列的前 n 项的和”。
这个概念其实很容易理解,即一个数组中,第 n 位存储的是数组前 n 个数字的和。
例如,对 [1,2,3,4,5,6] 来说,其前缀和就是 pre=[1,3,6,10,15,21]。
我们可以使用公式 pre[𝑖]=pre[𝑖−1]+nums[𝑖]得到每一位前缀和的值,从而通过前缀和进行相应的计算和解题。如果想得到某一个连续区间[l,r]的和则可以通过 pre[r] - pre[l-1] 取得,不过这里 l 需要 > 0。我们可以加一个特殊判断,如果 l = 0,区间 [l,r] 的和就是 pre[r]。
我们也可以在前缀和首项前面添加一个 0 省去这种特殊判断,算是一个小技巧吧。
其实前缀和的概念很简单,但困难的是如何在题目中使用前缀和以及如何使用前缀和的关系来进行解题。
母题 1
如果让你求一个数组的连续子数组总个数,你会如何求?其中连续指的是数组的索引连续。 比如 [1,3,4],其连续子数组有:[1], [3], [4], [1,3], [3,4] , [1,3,4],你需要返回 6。
一种思路是总的连续子数组个数等于:以索引为 0 结尾的子数组个数 + 以索引为 1 结尾的子数组个数 + … + 以索引为 n - 1 结尾的子数组个数,这无疑是完备的。
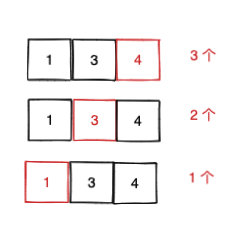
同时利用母题 0 的前缀和思路, 边遍历边求和。
参考代码(JS):
1 | function countSubArray(nums) { |
复杂度分析
- 时间复杂度:$O(N)$,其中 N 为数组长度。
- 空间复杂度:$O(1)$
而由于以索引为 i 结尾的子数组个数就是 i + 1,因此这道题可以直接用等差数列求和公式 (1 + n) * n / 2,其中 n 数组长度。
母题 2
我继续修改下题目, 如果让你求一个数组相邻差为 1 连续子数组的总个数呢?(如果只有一个数,那么我们也认为其实一个相邻差为 1 连续子数组)其实就是索引差 1 的同时,值也差 1。
和上面思路类似,无非就是增加差值的判断。
参考代码(JS):
1 | function countSubArray(nums) { |
复杂度分析
- 时间复杂度:$O(N)$,其中 N 为数组长度。
- 空间复杂度:$O(1)$
如果我值差只要大于 1 就行呢?其实改下符号就行了,这不就是求上升子序列个数么?这里不再继续赘述, 大家可以自己试试。
母题 3
我们继续扩展。
如果我让你求出不大于 k 的子数组的个数呢?不大于 k 指的是子数组的全部元素都不大于 k。 比如 [1,3,4] 子数组有 [1], [3], [4], [1,3], [3,4] , [1,3,4],不大于 3 的子数组有 [1], [3], [1,3] ,那么 [1,3,4] 不大于 3 的子数组个数就是 3。 实现函数 atMostK(k, nums)。
参考代码(JS):
1 | function countSubArray(k, nums) { |
复杂度分析
- 时间复杂度:$O(N)$,其中 N 为数组长度。
- 空间复杂度:$O(1)$
母题 4
如果我让你求出子数组最大值刚好是 k 的子数组的个数呢? 比如 [1,3,4] 子数组有 [1], [3], [4], [1,3], [3,4] , [1,3,4],子数组最大值刚好是 3 的子数组有 [3], [1,3] ,那么 [1,3,4] 子数组最大值刚好是 3 的子数组个数就是 2。实现函数 exactK(k, nums)。
实际上是 exactK 可以直接利用 atMostK,即 atMostK(k) - atMostK(k - 1),原因见下方母题 5 部分。
母题 5
如果我让你求出子数组最大值刚好是 介于 k1 和 k2 的子数组的个数呢?实现函数 betweenK(k1, k2, nums)。
实际上是 betweenK 可以直接利用 atMostK,即 atMostK(k1, nums) - atMostK(k2 - 1, nums),其中 k1 > k2。前提是值是离散的, 比如上面我出的题都是整数。 因此我可以直接 减 1,因为 1 是两个整数最小的间隔。
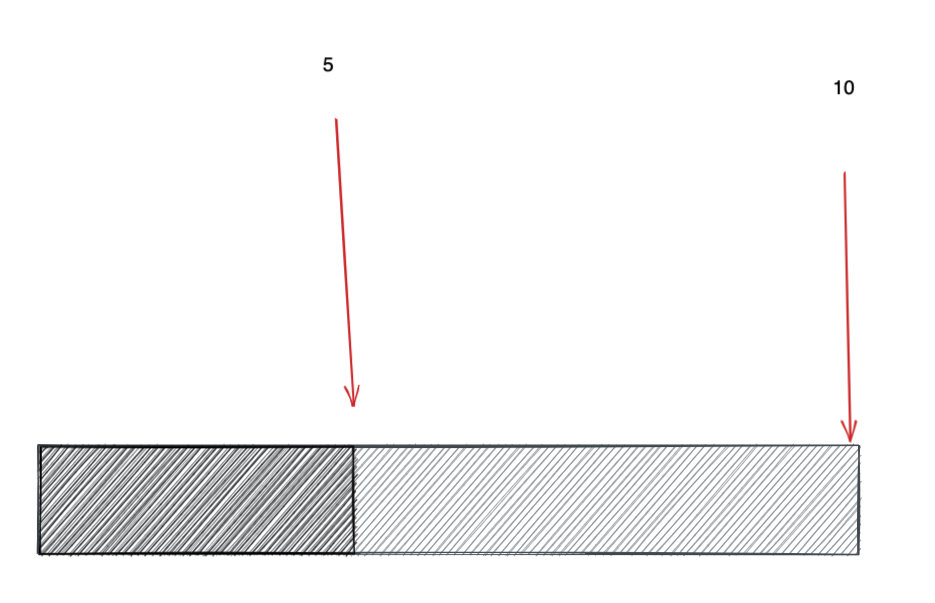
如上,小于等于 10 的区域减去 小于 5 的区域就是 大于等于 5 且小于等于 10 的区域。
注意我说的是小于 5, 不是小于等于 5。 由于整数是离散的,最小间隔是 1。因此小于 5 在这里就等价于 小于等于 4。这就是 betweenK(k1, k2, nums) = atMostK(k1) - atMostK(k2 - 1) 的原因。
因此不难看出 exactK 其实就是 betweenK 的特殊形式。 当 k1 == k2 的时候, betweenK 等价于 exactK。
因此 atMostK 就是灵魂方法,一定要掌握,不明白建议多看几遍。
前缀和的使用场景
上面是前缀和的基本概念以及简单使用。这里,我们总结一下前缀和的常见使用场景。大家碰到类似场景,不妨思考一下是否可通过前缀和以空间换时间的方式解决。
- 差分(后面我们要讲的 1109. 航班预订统计 就使用了这个技巧)
- 前缀和与二分。如果 nums 是一个正整数数组,那么其前缀和一定是单调递增的,有时候可以利用这个性质做二分。
- 求区间内的 1 的个数。比如给你一个数组 nums,让你求任意区间的 1 的个数。那么就可以先预处理,比如将 1 以外的数字预处理为 0,然后做前缀和,最后做差求区间和,这样区间和就是 1 的个数。(比如 1871. 跳跃游戏 VII 就利用了这个技巧)
- 区间值计数。上面是对 nums 区间本身进行统计。如果我想求 nums 的值(注意是值,不是索引)在 [lower,upper] 之间的数有多少,怎么求呢?我们可以开辟一个与 nums 值域大小等大的数组,并对值进行计数(即统计 nums 的值的出现频率),接下来就和普通前缀和一样了。(比如 1862. 向下取整数对和 就利用了这个技巧)
- 区间值计数扩展。上面的区间值计数没有对索引进行限制,那如果我加了索引的限制呢?比如我想求索引在 [l,r] 并且值在 [lower,upper]的值的个数如何求?我们可以先做一个二维前缀和 pre[i][j] 表示 前 i 项 j 的出现次数(显然 pre 的规模为数组长度乘以数组值域大小),接下来依次枚举 [lower,upper]的所有数 cur,并利用 pre[r][cur] - pre[l-1][cur],将结果进行累加即可。(比如1906. 查询差绝对值的最小值 就使用了这个技巧)
有了上面的铺垫, 我们来看下第一道题。
467. 环绕字符串中唯一的子字符串(中等)
题目描述
1 | 把字符串 s 看作是“abcdefghijklmnopqrstuvwxyz”的无限环绕字符串,所以 s 看起来是这样的:"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd....". |
前置知识
- 滑动窗口
思路
题目是让我们找 p 在 s 中出现的非空子串数目,而 s 是固定的一个无限循环字符串。由于 p 的数据范围是 10^5 ,因此暴力找出所有子串就需要 10^10 次操作了,应该会超时。而且题目很多信息都没用到,肯定不对。
仔细看下题目发现,这不就是母题 2 的变种么?话不多说, 直接上代码,看看有多像。
为了减少判断, 我这里用了一个黑科技, p 前面加了个
^。
1 | class Solution: |
如上代码是有问题。 比如 cac会被计算为 3,实际上应该是 2。根本原因在于 c 被错误地计算了两次。因此一个简单的思路就是用 set 记录一下访问过的子字符串即可。比如:
1 | { |
而由于 set 中的元素一定是连续的,因此上面的数据也可以用 hashmap 存:
1 | { |
含义是:
- 以 b 结尾的子串最大长度为 1,也就是 b。
- 以 c 结尾的子串最大长度为 3,也就是 abc。
- 以 d 结尾的子串最大长度为 4,也就是 abcd。
至于 c ,是没有必要存的。我们可以通过母题 2 的方式算出来。
具体算法:
- 定义一个 len_mapper。key 是 字母, value 是 长度。 含义是以 key 结尾的最长连续子串的长度。
关键字是:最长
- 用一个变量 w 记录连续子串的长度,遍历过程根据 w 的值更新 len_mapper
- 返回 len_mapper 中所有 value 的和。
比如: abc,此时的 len_mapper 为:
1 | { |
再比如:abcab,此时的 len_mapper 依旧。
再比如: abcazabc,此时的 len_mapper:
1 | { |
这就得到了去重的目的。这种算法是不重不漏的,因为最长的连续子串一定是包含了比它短的连续子串,这个思想和 1297. 子串的最大出现次数 剪枝的方法有异曲同工之妙。
代码(Python)
1 | class Solution: |
复杂度分析
- 时间复杂度:$O(N)$,其中 $N$ 为字符串 p 的长度。
- 空间复杂度:由于最多存储 26 个字母, 因此空间实际上是常数,故空间复杂度为 $O(1)$。
795. 区间子数组个数(中等)
题目描述
1 |
|
前置知识
- 滑动窗口
思路
由母题 5,我们知道 betweenK 可以直接利用 atMostK,即 atMostK(k1) - atMostK(k2 - 1),其中 k1 > k2。
由母题 2,我们知道如何求满足一定条件(这里是元素都小于等于 R)子数组的个数。
这两个结合一下, 就可以解决。
代码(Python)
代码是不是很像
1 | class Solution: |
_复杂度分析_
- 时间复杂度:$O(N)$,其中 $N$ 为数组长度。
- 空间复杂度:$O(1)$。
904. 水果成篮(中等)
题目描述
1 | 在一排树中,第 i 棵树产生 tree[i] 型的水果。 |
前置知识
- 滑动窗口
思路
题目花里胡哨的。我们来抽象一下,就是给你一个数组, 让你选定一个子数组, 这个子数组最多只有两种数字,这个选定的子数组最大可以是多少。
这不就和母题 3 一样么?只不过 k 变成了固定值 2。另外由于题目要求整个窗口最多两种数字,我们用哈希表存一下不就好了吗?
set 是不行了的。 因此我们不但需要知道几个数字在窗口, 我们还要知道每个数字出现的次数,这样才可以使用滑动窗口优化时间复杂度。
代码(Python)
1 | class Solution: |
复杂度分析
- 时间复杂度:$O(N)$,其中 $N$ 为数组长度。
- 空间复杂度:$O(k)$。
992. K 个不同整数的子数组(困难)
题目描述
1 | 给定一个正整数数组 A,如果 A 的某个子数组中不同整数的个数恰好为 K,则称 A 的这个连续、不一定独立的子数组为好子数组。 |
前置知识
- 滑动窗口
思路
由母题 5,知:exactK = atMostK(k) - atMostK(k - 1), 因此答案便呼之欲出了。其他部分和上面的题目 904. 水果成篮 一样。
实际上和所有的滑动窗口题目都差不多。
代码(Python)
1 | class Solution: |
复杂度分析
- 时间复杂度:$O(N)$,中 $N$ 为数组长度。
- 空间复杂度:$O(k)$。
1109. 航班预订统计(中等)
题目描述
1 |
|
前置知识
- 前缀和
思路
这道题的题目描述不是很清楚。我简单分析一下题目:
[i, j, k] 其实代表的是 第 i 站上来了 k 个人, 一直到 第 j 站都在飞机上,到第 j + 1 就不在飞机上了。所以第 i 站到第 j 站的每一站都会因此多 k 个人。
理解了题目只会不难写出下面的代码。
1 | class Solution: |
如上的代码复杂度太高,无法通过全部的测试用例。
注意到里层的 while 循环是连续的数组全部加上一个数字,不难想到可以利用母题 0 的前缀和思路优化。
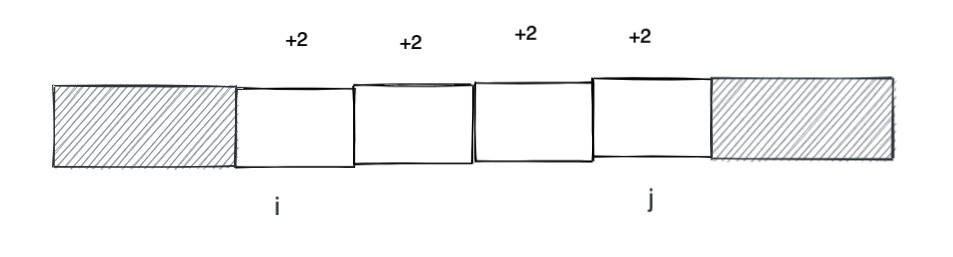
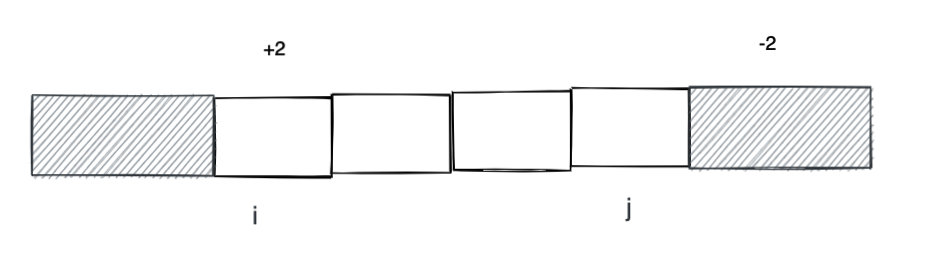
一种思路就是在 i 的位置 + k, 然后利用前缀和的技巧给 i 到 n 的元素都加上 k。但是题目需要加的是一个区间, j + 1 及其之后的元素会被多加一个 k。一个简单的技巧就是给 j + 1 的元素减去 k,这样正负就可以抵消。
- 拼车 是这道题的换皮题, 思路一模一样。
代码(Python)
1 | class Solution: |
复杂度分析
- 时间复杂度:$O(N)$,中 $N$ 为数组长度。
- 空间复杂度:$O(N)$。
总结
这几道题都是滑动窗口和前缀和的思路。力扣类似的题目还真不少,大家只有多留心,就会发现这个套路。
前缀和的技巧以及滑动窗口的技巧都比较固定,且有模板可套。 难点就在于我怎么才能想到可以用这个技巧呢?
我这里总结了两点:
- 找关键字。比如题目中有连续,就应该条件反射想到滑动窗口和前缀和。比如题目求最大最小就想到动态规划和贪心等等。想到之后,就可以和题目信息对比快速排除错误的算法,找到可行解。这个思考的时间会随着你的题感增加而降低。
- 先写出暴力解,然后找暴力解的瓶颈, 根据瓶颈就很容易知道应该用什么数据结构和算法去优化。
最后推荐几道类似的题目, 供大家练习,一定要自己写出来才行哦。
- 303. 区域和检索 - 数组不可变
- 1171. 从链表中删去总和值为零的连续节点
- 1186.删除一次得到子数组最大和
- 1310. 子数组异或查询
- 1371. 每个元音包含偶数次的最长子字符串
- 1402. 做菜顺序
大家对此有何看法,欢迎给我留言,我有时间都会一一查看回答。
更多算法套路可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 36K star 啦。
大家也可以关注我的公众号《力扣加加》带你啃下算法这块硬骨头。
