
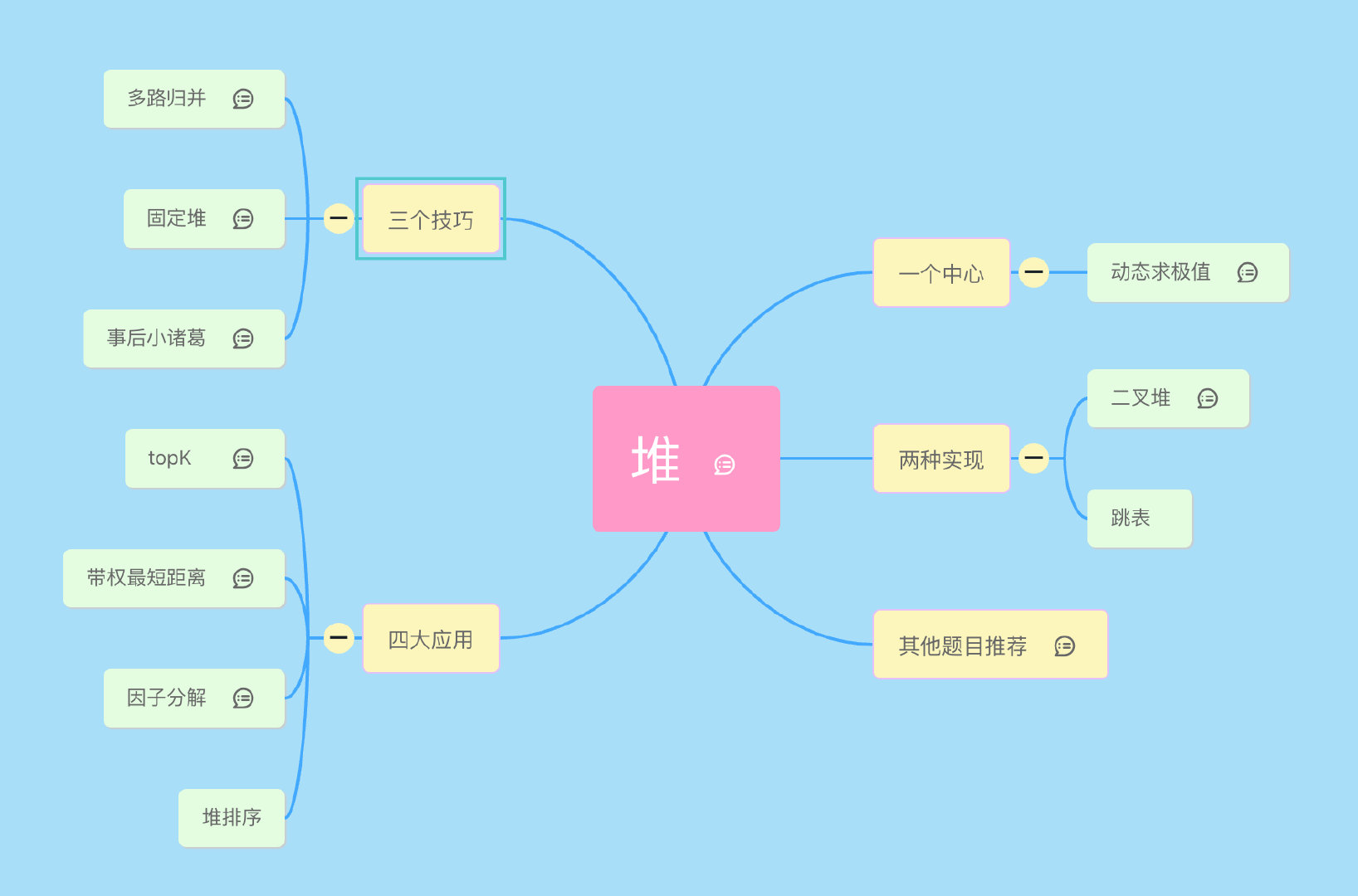
大家好,我是 lucifer。今天给大家带来的是《堆》专题。先上下本文的提纲,这个是我用 mindmap 画的一个脑图,之后我会继续完善,将其他专题逐步完善起来。
大家也可以使用 vscode blink-mind 打开源文件查看,里面有一些笔记可以点开查看。源文件可以去我的公众号《力扣加加》回复脑图获取,以后脑图也会持续更新更多内容。vscode 插件地址:https://marketplace.visualstudio.com/items?itemName=awehook.vscode-blink-mind
本系列包含以下专题:
- 几乎刷完了力扣所有的链表题,我发现了这些东西。。。
- 几乎刷完了力扣所有的树题,我发现了这些东西。。。
- 几乎刷完了力扣所有的堆题,我发现了这些东西。。。(就是本文)
一点絮叨
堆标签在 leetcode 一共有 42 道题。 为了准备这个专题,我将 leetcode 几乎所有的堆题目都刷了一遍。
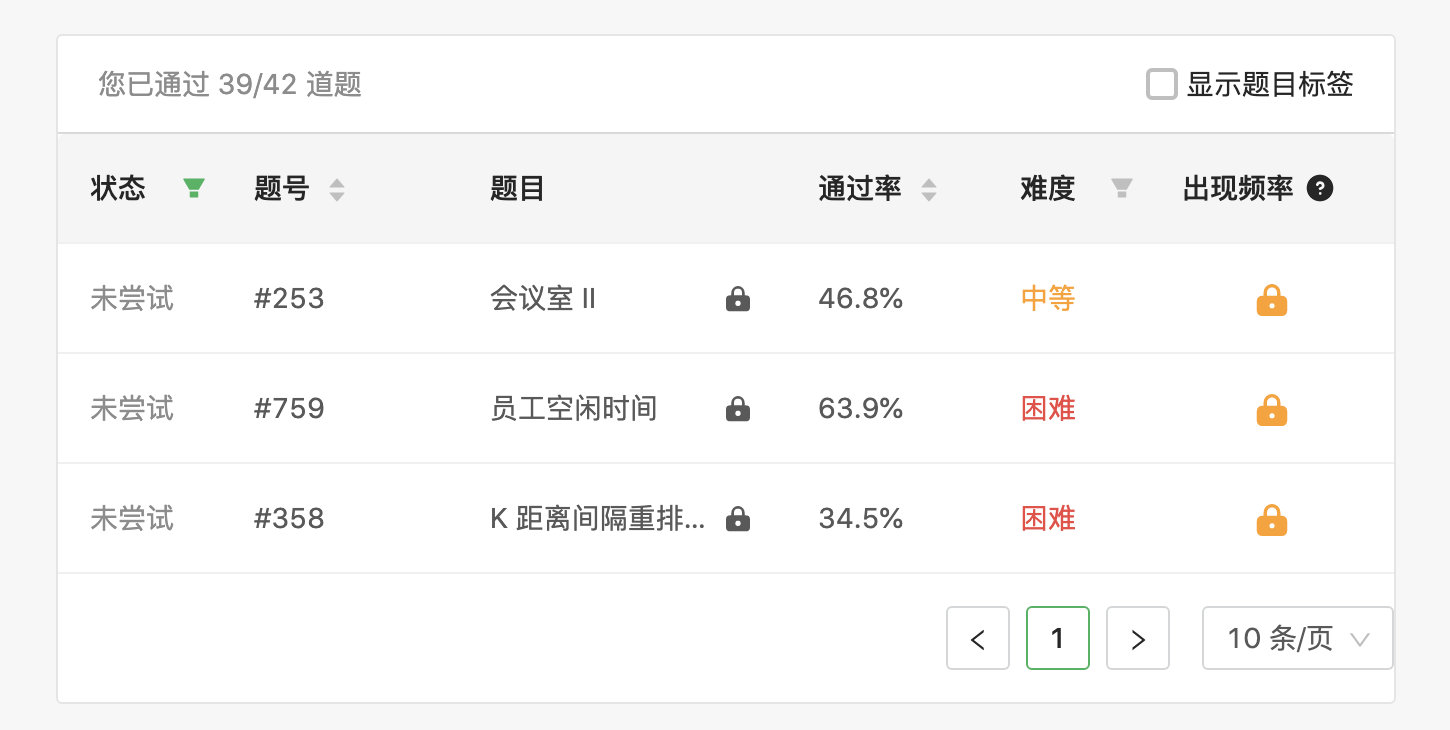
可以看出,除了 3 个上锁的,其他我都刷了一遍。通过集中刷这些题,我发现了一些有趣的信息,今天就分享给大家。
需要注意的是,本文不对堆和优先队列进行区分。因此本文提到的堆和优先队列大家可以认为是同一个东西。如果大家对两者的学术区别感兴趣,可以去查阅相关资料。
如果不做特殊说明,本文的堆均指的是小顶堆。
堆的题难度几何?
堆确实是一个难度不低的专题。从官方的难度标签来看,堆的题目一共才 42 道,困难度将近 50%。没有对比就没有伤害,树专题困难度只有不到 10%。
从通过率来看,一半以上的题目平均通过率在 50% 以下。作为对比, 树的题目通过率在 50% 以下的只有不到三分之一。
不过大家不要太有压力。lucifer 给大家带来了一个口诀一个中心,两种实现,三个技巧,四大应用,我们不仅讲实现和原理,更讲问题的背景以及套路和模板。
文章里涉及的模板大家随时都可以从我的力扣刷题插件 leetcode-cheatsheet 中获取。
堆的使用场景分析
堆其实就是一种数据结构,数据结构是为了算法服务的,那堆这种数据结构是为哪种算法服务的?它的适用场景是什么? 这是每一个学习堆的人第一个需要解决的问题。
在什么情况下我们会使用堆呢?堆的原理是什么?如何实现一个堆?别急,本文将一一为你揭秘。
在进入正文之前,给大家一个学习建议 - 先不要纠结堆怎么实现的,咱先了解堆解决了什么问题。当你了解了使用背景和解决的问题之后,然后当一个调包侠,直接用现成的堆的 api 解决问题。等你理解得差不多了,再去看堆的原理和实现。我就是这样学习堆的,因此这里就将这个学习经验分享给你。
为了对堆的使用场景进行说明,这里我虚拟了一个场景。
下面这个例子很重要, 后面会反复和这个例子进行对比。
一个挂号系统
问题描述
假如你是一个排队挂号系统的技术负责人。该系统需要给每一个前来排队的人发放一个排队码(入队),并根据先来后到的原则进行叫号(出队)。
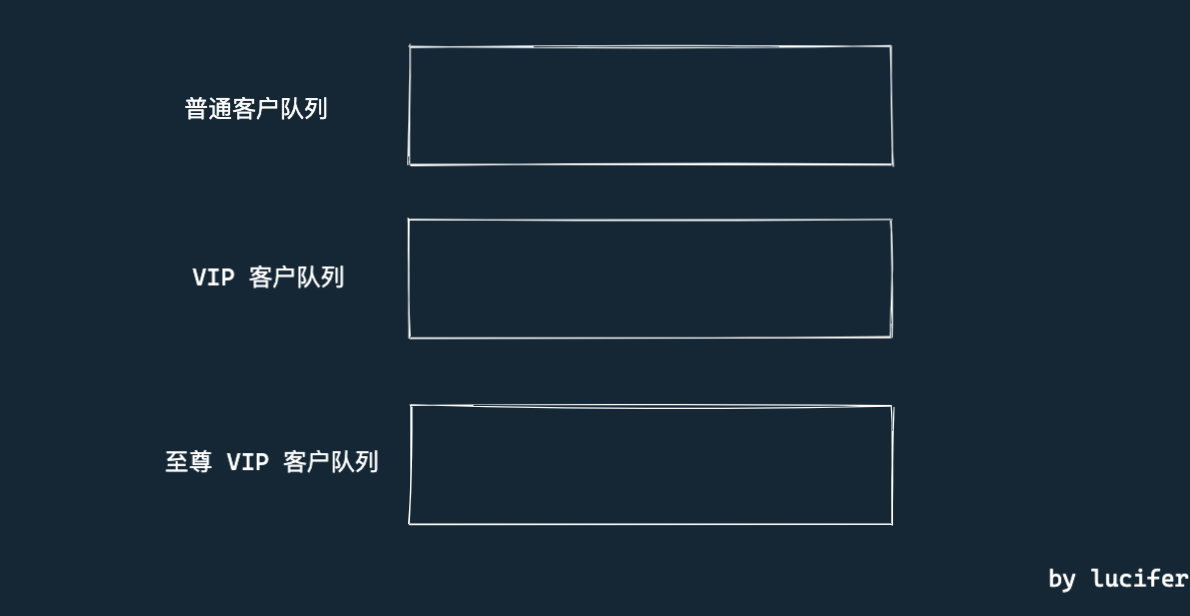
除此之外,我们还可以区分了几种客户类型, 分别是普通客户, VIP 客户 和 至尊 VIP 客户。
- 如果不同的客户使用不同的窗口的话,我该如何设计实现我的系统?(大家获得的服务不一样,比如 VIP 客户是专家级医生,普通客户是普通医生)
- 如果不同的客户都使用一个窗口的话,我该如何设计实现我的系统?(大家获得的服务都一样,但是优先级不一样。比如其他条件相同情况下(比如他们都是同时来挂号的),VIP 客户 优先级高于普通客户)
我该如何设计我的系统才能满足需求,并获得较好的扩展性?
初步的解决方案
如果不同的客户使用不同的窗口。那么我们可以设计三个队列,分别存放正在排队的三种人。这种设计满足了题目要求,也足够简单。
如果我们只有一个窗口,所有的病人需要使用同一个队列,并且同样的客户类型按照上面讲的先到先服务原则,但是不同客户类型之间可能会插队。
简单起见,我引入了虚拟时间这个概念。具体来说:
- 普通客户的虚拟时间就是真实时间。
- VIP 客户的虚拟时间按照实际到来时间减去一个小时。比如一个 VIP 客户是 14:00 到达的,我认为他是 13:00 到的。
- 至尊 VIP 客户的虚拟时间按照实际到来时间减去两个小时。比如一个 至尊 VIP 客户是 14:00 到达的,我认为他是 12:00 到的。
这样,我们只需要按照上面的”虚拟到达时间“进行先到先服务即可。
因此我们就可以继续使用刚才的三个队列的方式,只不过队列存储的不是真实时间,而是虚拟时间。每次开始叫号的时候,我们使用虚拟时间比较,虚拟时间较小的先服务即可。
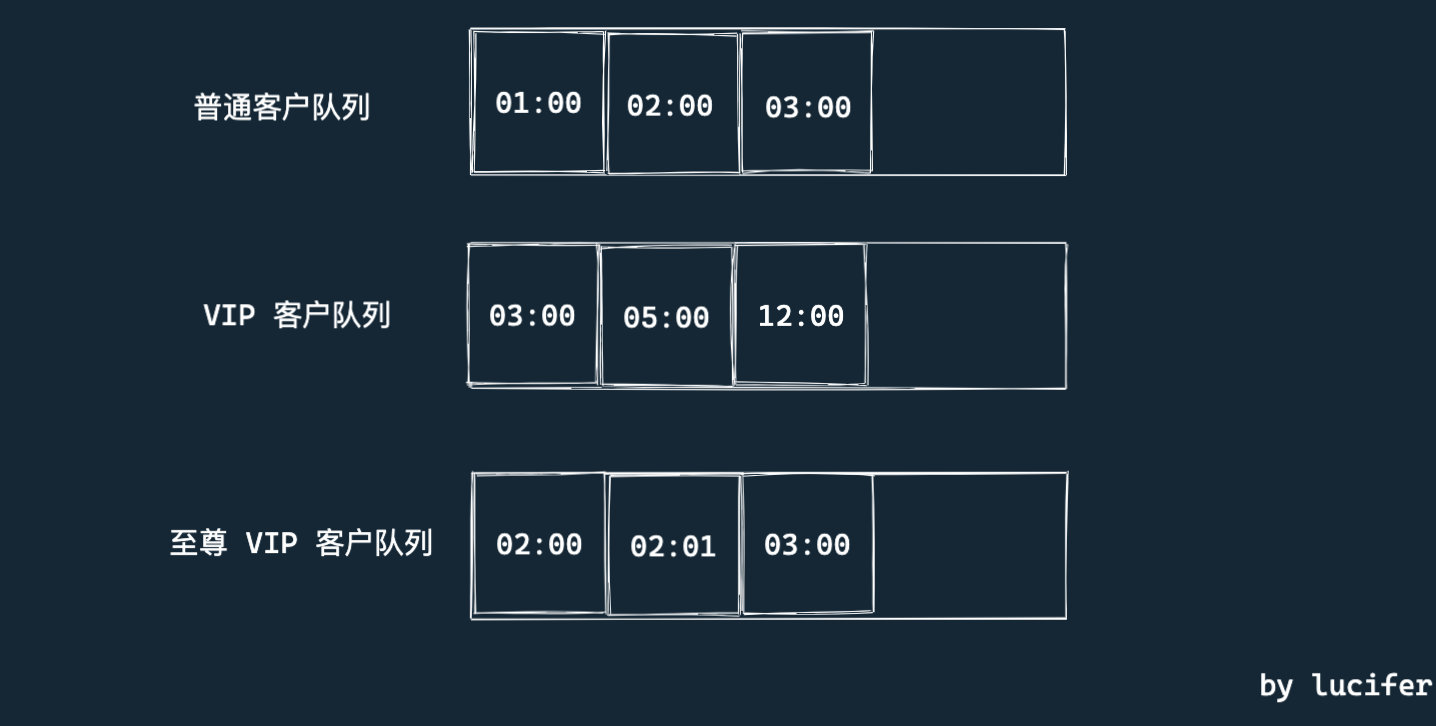
不难看出,队列内部的时间都是有序。
而这里的虚拟时间,其实就是优先队列中的优先权重,虚拟时间越小,权重越大。
可以插队怎么办?
这种算法很好地完成了我们的需求,复杂度相当不错。不过事情还没有完结,这一次我们又碰到新的产品需求:
- 如果有别的门诊的病人转院到我们的诊所,则按照他之前的排队信息算,比如 ta 是 12:00 在别的院挂的号,那么转到本院仍然是按照 12:00 挂号算。
- 如果被叫到号三分钟没有应答,将其作废。但是如果后面病人重新来了,则认为他是当前时间减去一个小时的虚拟时间再次排队。比如 ta 是 13:00 被叫号,没有应答,13:30 又回来,则认为他是 12:30 排队的,重新进队列。
这样就有了”插队“的情况了。该怎么办呢?一个简单的做法是,将其插入到正确位置,并重新调整后面所有人的排队位置。
如下图是插入一个 1:30 开始排队的普通客户的情况。
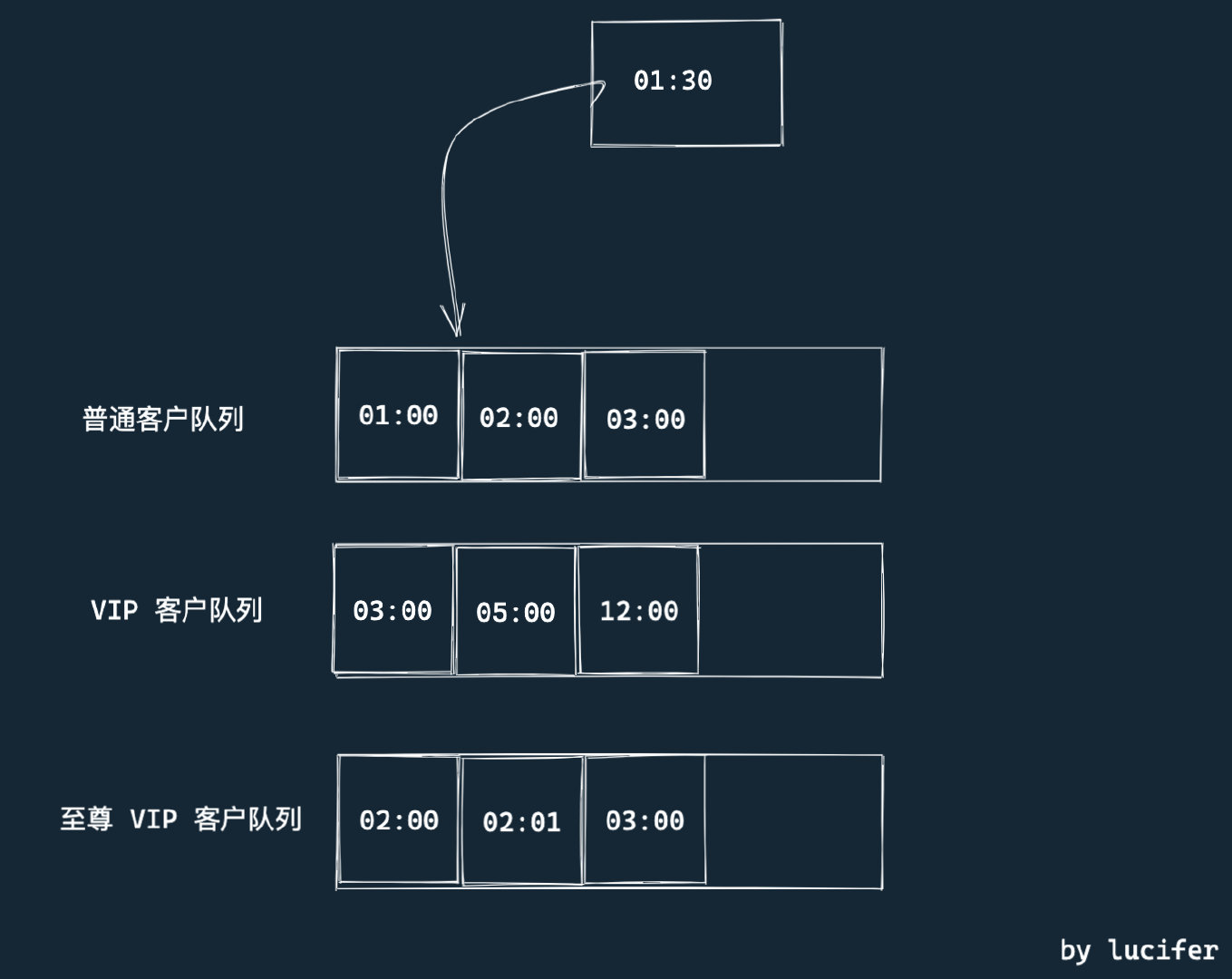
(查找插入位置)
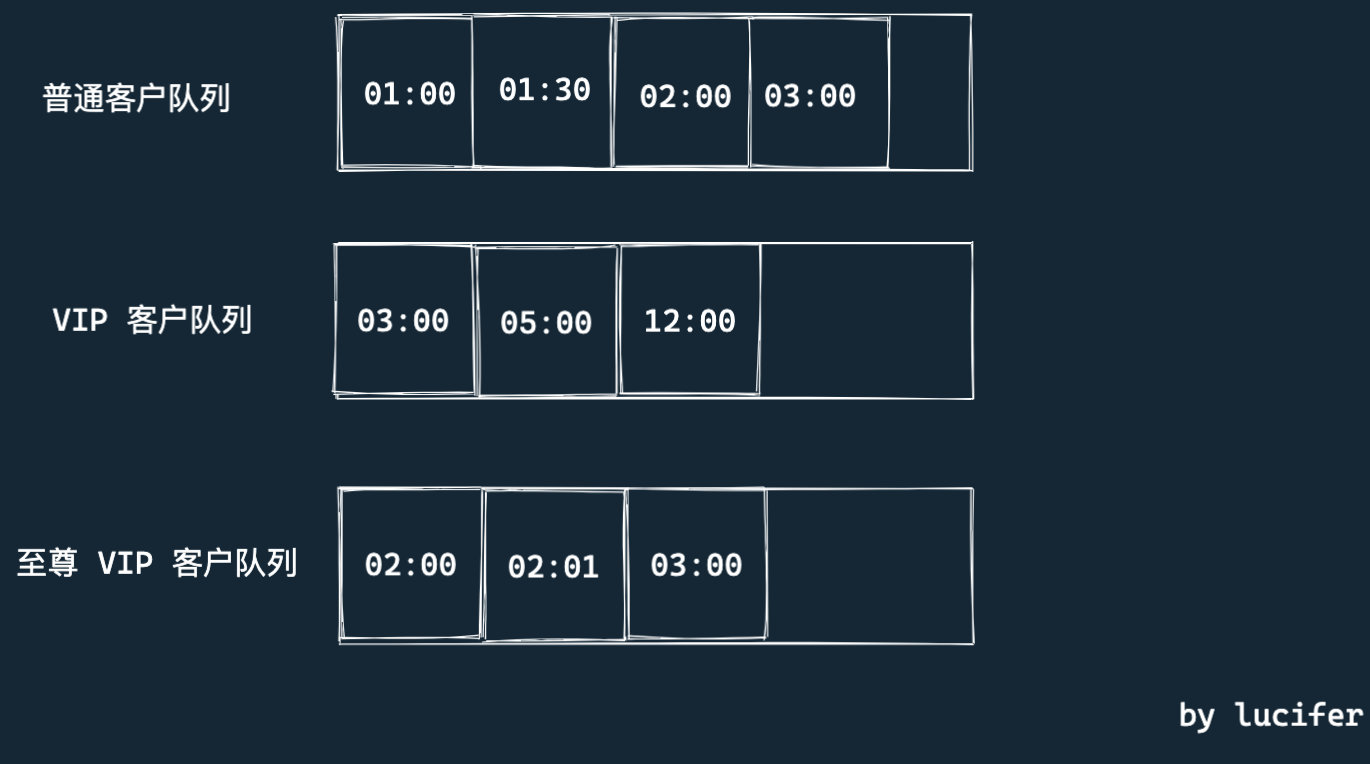
(将其插入)
如果队列使用数组实现, 上面插队过程的时间复杂度为 $O(N)$,其中 $N$ 为被插队的队伍长度。如果队伍很长,那么调整的次数明显增加。
不过我们发现,本质上我们就是在维护一个有序列表,而使用数组方式去维护有序列表的好处是可以随机访问,但是很明显这个需求并不需要这个特性。如果使用链表去实现,那么时间复杂度理论上是 $O(1)$,但是如何定位到需要插入的位置呢?朴素的思维是遍历查找,但是这样的时间复杂度又退化到了 $O(N)$。有没有时间复杂度更好的做法呢?答案就是本文的主角优先队列。
上面说了链表的实现核心在于查找也需要 $O(N)$,我们可以优化这个过程吗?实际上这就是优先级队列的链表实现,由于是有序的,我们可以用跳表加速查找,时间复杂度可以优化到 $O(logN)$。
其实算法界有很多类似的问题。比如建立数据库索引的算法,如果给某一个有序的列添加索引,不能每次插入一条数据都去调整所有的数据吧(上面的数组实现)?因此我们可以用平衡树来实现,这样每次插入可以最多调整 $(O(logN))$。优先队列的另外一种实现 - 二叉堆就是这个思想,时间复杂度也可以优化到 $O(logN)$
本文只讲解常见的二叉堆实现,对于跳表和红黑树不再这里讲。 关于优先队列的二叉堆实现,我们会在后面给大家详细介绍。这里大家只有明白优先队列解决的问题是什么就可以了。
使用堆解决问题
堆的两个核心 API 是 push 和 pop。
大家先不考虑它怎么实现的,你可以暂时把 ta 想象成一个黑盒,提供了两个 api:
push: 推入一个数据,内部怎么组织我不管。对应我上面场景里面的排队和插队。pop: 弹出一个数据,该数据一定是最小的,内部怎么实现我不管。对应我上面场景里面的叫号。
这里的例子其实是小顶堆。而如果弹出的数据一定是最大的,那么对应的实现为大顶堆。
借助这两个 api 就可以实现上面的需求。
1 | # 12:00 来了一个普通的顾客(push) |
小结
上面这个场景单纯使用数组和链表都可以满足需求,但是使用其他数据结构在应对”插队“的情况表现地会更好。
具体来说:
如果永远都维护一个有序数组的方式取极值很容易,但是插队麻烦。
如果永远都维护一个有序链表的方式取极值也容易。 不过要想查找足够快,而不是线性扫描,就需要借助索引,这种实现对应的就是优先级队列的跳表实现。
如果永远都维护一个树的方式取极值也可以实现,比如根节点就是极值,这样 O(1) 也可以取到极值,但是调整过程需要 $O(logN)$。这种实现对应的就是优先级队列的二叉堆实现。
简单总结下就是,堆就是动态帮你求极值的。当你需要动态求最大或最小值就就用它。而具体怎么实现,复杂度的分析我们之后讲,现在你只要记住使用场景,堆是如何解决这些问题的以及堆的 api 就够了。
队列 VS 优先队列
上面通过一个例子带大家了解了一下优先队列。那么在接下来讲具体实现之前,我觉得有必要回答下一个大家普遍关心的问题,那就是优先队列是队列么?
很多人觉得队列和优先队列是完全不同的东西,就好像 Java 和 JavaScript 一样,我看了很多文章都是这么说的。
而我不这么认为。实际上,普通的队列也可以看成是一个特殊的优先级队列, 这和网上大多数的说法优先级队列和队列没什么关系有所不同。我认为队列无非就是以时间这一变量作为优先级的优先队列,时间越早,优先级越高,优先级越高越先出队。
大家平时写 BFS 的时候都会用到队列来帮你处理节点的访问顺序。那使用优先队列行不行?当然可以了!我举个例子:
例题 - 513. 找树左下角的值
题目描述
1 | 定一个二叉树,在树的最后一行找到最左边的值。 |
思路
我们可以使用 BFS 来做一次层次遍历,并且每一层我们都从右向左遍历,这样层次遍历的最后一个节点就是树左下角的节点。
常规的做法是使用双端队列(就是队列)来实现,由于队列的先进先出原则很方便地就能实现层次遍历的效果。
代码
对于代码看不懂的同学,可以先不要着急。等完整读完本文之后再回过头看会容易很多。下同,不再赘述。
Python Code:
1 | class Solution: |
实际上, 我们也可以使用优先队列的方式,思路和代码也几乎和上面完全一样。
1 | class Solution: |
小结
所有使用队列的地方,都可以使用优先队列来完成,反之却不一定。
既然优先队列这么厉害,那平时都用优先队列不就行了?为啥使用队列的地方没见过别人用堆呢?最核心的原因是时间复杂度更差了。
比如上面的例子,本来入队和出队都可是很容易地在 $O(1)$ 的时间完成。而现在呢?入队和出队的复杂度都是 $O(logN)$,其中 N 为当前队列的大小。因此在没有必要的地方使用堆,会大大提高算法的时间复杂度,这当然不合适。说的粗俗一点就是脱了裤子放屁。
不过 BFS 真的就没人用优先队列实现么?当然不是!比如带权图的最短路径问题,如果用队列做 BFS 那就需要优先队列才可以,因为路径之间是有权重的差异的,这不就是优先队列的设计初衷么。使用优先队列的 BFS 实现典型的就是 dijkstra 算法。
这再一次应征了我的那句话队列就是一种特殊的优先队列而已。特殊到大家的权重就是按照到来的顺序定,谁先来谁的优先级越高。在这种特殊情况下,我们没必须去维护堆来完成,进而获得更好的时间复杂度。
一个中心
堆的问题核心点就一个,那就是动态求极值。动态和极值二者缺一不可。
求极值比较好理解,无非就是求最大值或者最小值,而动态却不然。比如要你求一个数组的第 k 小的数,这是动态么?这其实完全看你怎么理解。而在我们这里,这种情况就是动态的。
如何理解上面的例子是动态呢?
你可以这么想。由于堆只能求极值。比如能求最小值,但不能直接求第 k 小的值。
那我们是不是先求最小的值,然后将其出队(对应上面例子的叫号)。然后继续求最小的值,这个时候求的就是第 2 小了。如果要求第 k 小,那就如此反复 k 次即可。
这个过程,你会发现数据是在动态变化的,对应的就是堆的大小在变化。
接下来,我们通过几个例子来进行说明。
例一 - 1046. 最后一块石头的重量
题目描述
1 | 有一堆石头,每块石头的重量都是正整数。 |
思路
题目比较简单,直接模拟即可。需要注意的是,每次选择两个最重的两个石头进行粉碎之后,最重的石头的重量便发生了变化。这会影响到下次取最重的石头。简单来说就是最重的石头在模拟过程中是动态变化的。
这种动态取极值的场景使用堆就非常适合。
当然看下这个数据范围
1 <= stones.length <= 30 且 1 <= stones[i] <= 1000,使用计数的方式应该也是可以的。
代码
Java Code:
1 | import java.util.PriorityQueue; |
例二 - 313. 超级丑数
题目描述
1 | 编写一段程序来查找第 n 个超级丑数。 |
思路
这道题看似和动态求极值没关系。其实不然,让我们来分析一下这个题目。
我们可以实现生成超级多的丑数,比如先从小到大生成 N 个丑数,然后直接取第 N 个么?
拿这道题来说, 题目有一个数据范围限制 0 < n ≤ 10^6,那我们是不是预先生成一个大小为 $10^6$ 的超级丑数数组,这样我们就可通过 $O(1)$ 的时间获取到第 N 个超级丑数了。
首先第一个问题就是时间和空间浪费。我们其实没有必要每次都计算所有的超级丑数,这样的预处理空间和时间都很差。
第二个问题是,我们如何生成 $10^6$ 以为的超级丑数呢?
通过丑数的定义,我们能知道超级丑数一定可以写出如下形式。
1 | if primes = [a,b,c,....] |
不妨将问题先做一下简化处理。考虑题目给的例子:[2,7,13,19]。
我们可以使用四个指针来处理。直接看下代码吧:
1 | public class Solution { |
这个技巧我自己称之为多路归并(实现想不到什么好的名字),我也会在后面的三个技巧也会对此方法使用堆来优化。
由于这里的指针是动态的,指针的数量其实和题目给的 primes 数组长度一致。因此实际上,我们可以使用记忆化递归的形式来完成,递归体和递归栈分别维护一个迭代变量即可。而这道题其实可以看出是一个状态机,因此使用动态规划来解决是符合直觉的。而这里,介绍一种堆的解法,相比于动态规划,个人认为更简单和符合直觉。
关于状态机,我这里有一篇文章原来状态机也可以用来刷 LeetCode?,大家可以参考一下哦。
实际上,我们可以动态维护一个当前最小的超级丑数。找到第一个, 我们将其移除,再找下一个当前最小的超级丑数(也就是全局第二小的超级丑数)。这样经过 n 轮,我们就得到了第 n 小的超级丑数。这种动态维护极值的场景正是堆的用武之地。
有没有觉得和上面石头的题目很像?
以题目给的例子 [2,7,13,19] 来说。
- 将 [2,7,13,19] 依次入堆。
- 出堆一个数字,也就是 2。这时取到了第一个超级丑数。
- 接着将 2 和 [2,7,13,19] 的乘积,也就是 [4,14,26,38] 依次入堆。
- 如此反复直到取到第 n 个超级丑数。
上面的正确性是毋庸置疑的,由于每次堆都可以取到最小的,每次我们也会将最小的从堆中移除。因此取 n 次自然就是第 n 大的超级丑数了。
堆的解法没有太大难度,唯一需要注意的是去重。比如 2 * 13 = 26,而 13 * 2 也是 26。我们不能将 26 入两次堆。解决的方法也很简单:
- 要么使用哈希表记录全部已经取出的数,对于已经取出的数字不再取即可。
- 另一种方法是记录上一次取出的数,由于取出的数字是按照数字大小不严格递增的,这样只需要拿上次取出的数和本次取出的数比较一下就知道了。
用哪种方法不用多说了吧?
代码
Java Code:
1 | class Solution { |
ans 初始化为 1 的作用相当于虚拟头,仅仅起到了简化操作的作用
小结
堆的中心就一个,那就是动态求极值。
而求极值无非就是最大值或者最小值,这不难看出。如果求最大值,我们可以使用大顶堆,如果求最小值,可以用最小堆。
而实际上,如果没有动态两个字,很多情况下没有必要使用堆。比如可以直接一次遍历找出最大的即可。而动态这个点不容易看出来,这正是题目的难点。这需要你先对问题进行分析, 分析出这道题其实就是动态求极值,那么使用堆来优化就应该被想到。类似的例子有很多,我也会在后面的小节给大家做更多的讲解。
两种实现
上面简单提到了堆的几种实现。这里介绍两种常见的实现,一种是基于链表的实现- 跳表,另一种是基于数组的实现 - 二叉堆。
使用跳表的实现,如果你的算法没有经过精雕细琢,性能会比较不稳定,且在数据量大的情况下内存占用会明显增加。 因此我们仅详细讲述二叉堆的实现,而对于跳表的实现,仅讲述它的基本原理,对于代码实现等更详细的内容由于比较偏就不在这里讲了。
跳表
跳表也是一种数据结构,因此 ta 其实也是服务于某种算法的。
跳表虽然在面试中出现的频率不大,但是在工业中,跳表会经常被用到。力扣中关于跳表的题目只有一个。但是跳表的设计思路值得我们去学习和思考。 其中有很多算法和数据结构技巧值得我们学习。比如空间换时间的思想,比如效率的取舍问题等。
上面提到了应付插队问题是设计堆应该考虑的首要问题。堆的跳表实现是如何解决这个问题的呢?
我们知道,不借助额外空间的情况下,在链表中查找一个值,需要按照顺序一个个查找,时间复杂度为 $O(N)$,其中 N 为链表长度。

(单链表)
当链表长度很大的时候, 这种时间是很难接受的。 一种常见的的优化方式是建立哈希表,将所有节点都放到哈希表中,以空间换时间的方式减少时间复杂度,这种做法时间复杂度为 $O(1)$,但是空间复杂度为 $O(N)$。
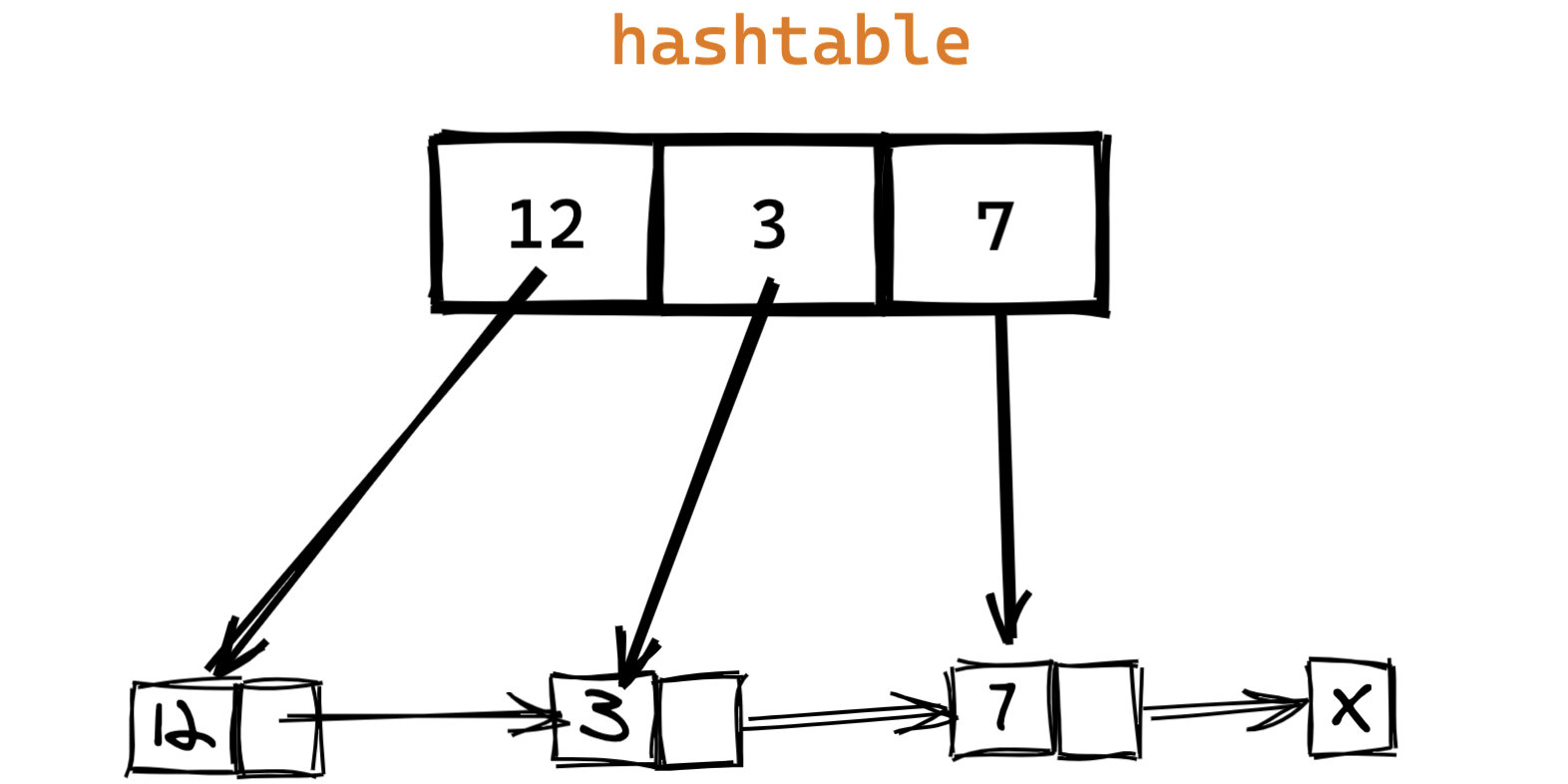
(单链表 + 哈希表)
为了防止链表中出现重复节点带来的问题,我们需要序列化节点,再建立哈希表,这种空间占用会更高,虽然只是系数级别的增加,但是这种开销也是不小的 。更重要的是,哈希表不能解决查找极值的问题,其仅适合根据 key 来获取内容。
为了解决上面的问题,跳表应运而生。
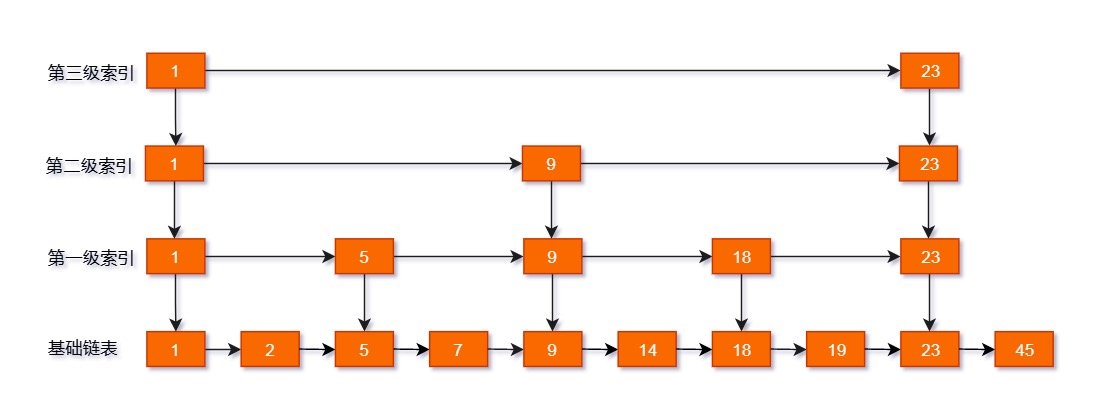
如下图所示,我们从链表中每两个元素抽出来,加一级索引,一级索引指向了原始链表,即:通过一级索引 7 的 down 指针可以找到原始链表的 7 。那怎么查找 10 呢?
注意这个算法要求链表是有序的。
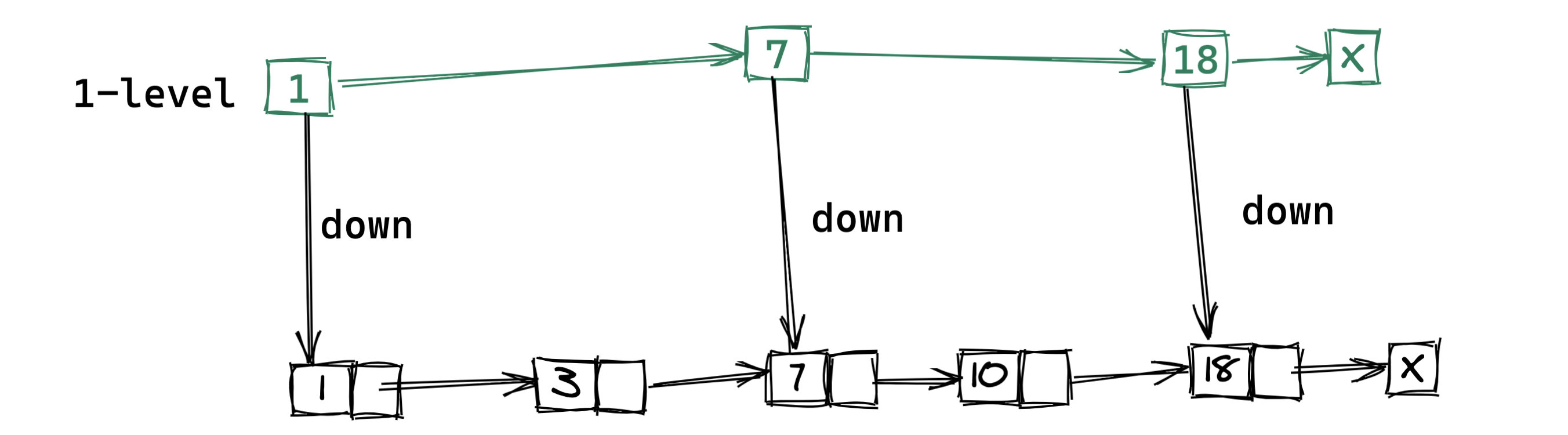
(建立一级索引)
我们可以:
- 通过现在一级跳表中搜索到 7,发现下一个 18 大于 10 ,也就是说我们要找的 10 在这两者之间。
- 通过 down 指针回到原始链表,通过原始链表的 next 指针我们找到了 10。
这个例子看不出性能提升。但是如果元素继续增大, 继续增加索引的层数,建立二级,三级。。。索引,使得链表能够实现二分查找,从而获得更好的效率。但是相应地,我们需要付出额外空间的代价。
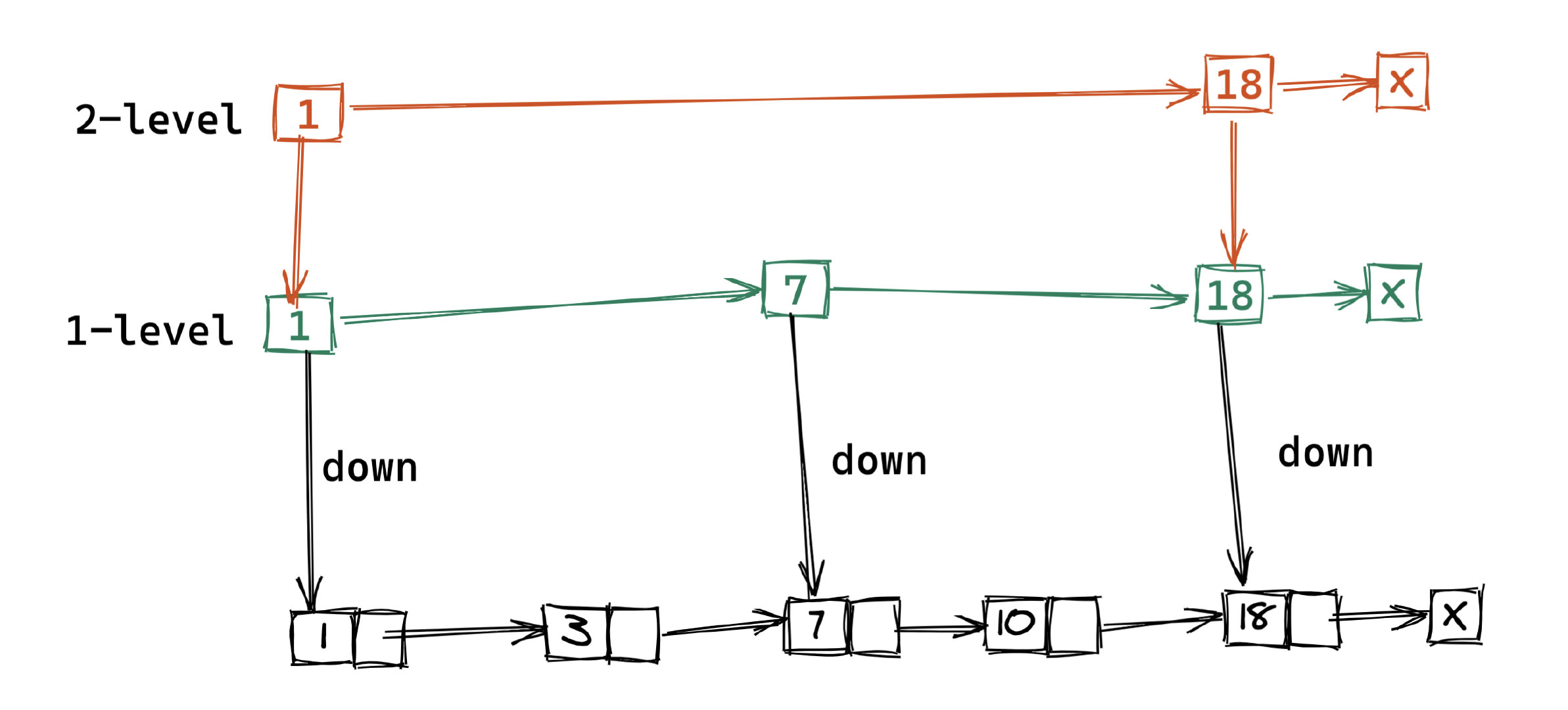
(增加索引层数)
理解了上面的点,你可以形象地将跳表想象为玩游戏的存档。
一个游戏有 10 关。如果我想要玩第 5 关的某一个地方,那么我可以直接从第五关开始,这样要比从第一关开始快。我们甚至可以在每一关同时设置很多的存档。这样我如果想玩第 5 关的某一个地方,也可以不用从第 5 关的开头开始,而是直接选择离你想玩的地方更近的存档,这就相当于跳表的二级索引。
跳表的时间复杂度和空间复杂度不是很好分析。由于时间复杂度 = 索引的高度 * 平均每层索引遍历元素的个数,而高度大概为 $logn$,并且每层遍历的元素是常数,因此时间复杂度为 $logn$,和二分查找的空间复杂度是一样的。
空间复杂度就等同于索引节点的个数,以每两个节点建立一个索引为例,大概是 n/2 + n/4 + n/8 + … + 8 + 4 + 2 ,因此空间复杂度是 $O(n)$。当然你如果每三个建立一个索引节点的话,空间会更省,但是复杂度不变。
理解了上面的内容,使用跳表实现堆就不难了。
- 入堆操作,只需要根据索引插到链表中,并更新索引(可选)。
- 出堆操作,只需要删除头部(或者尾部),并更新索引(可选)。
大家如果想检测自己的实现是否有问题,可以去力扣的1206. 设计跳表 检测。
接下来,我们看下一种更加常见的实现 - 二叉堆。
二叉堆
二叉堆的实现,我们仅讲解最核心的两个操作: heappop(出堆) 和 heappush(入堆)。对于其他操作不再讲解,不过我相信你会了这两个核心操作,其他的应该不是难事。
实现之后的使用效果大概是这样的:
1 | h = min_heap() |
基本原理
本质上来说,二叉堆就是一颗特殊的完全二叉树。它的特殊性只体现在一点,那就是父节点的权值不大于儿子的权值(小顶堆)。
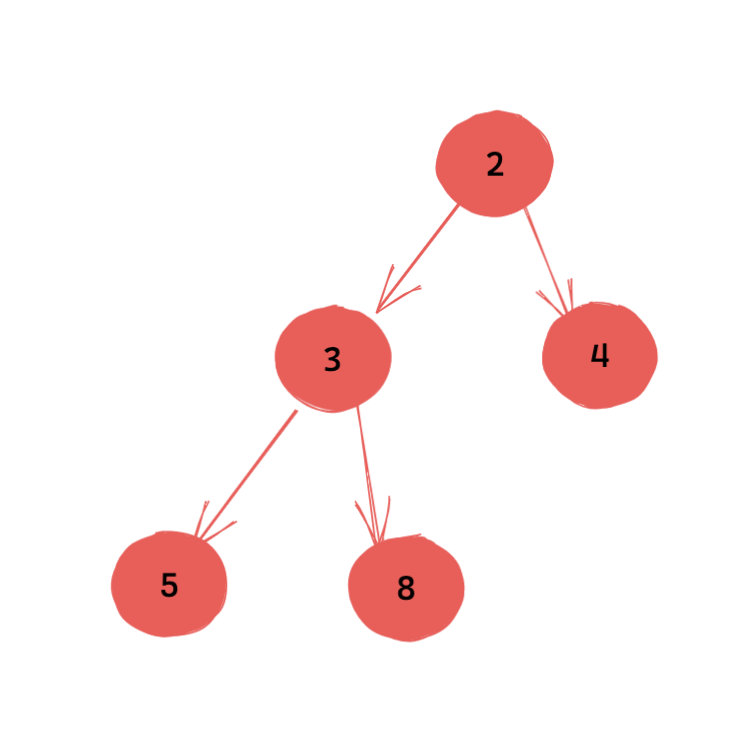
(一个小顶堆)
上面这句话需要大家记住,一切的一切都源于上面这句话。
由于父节点的权值不大于儿子的权值(小顶堆),那么很自然能推导出树的根节点就是最小值。这就起到了堆的取极值的作用了。
那动态性呢?二叉堆是怎么做到的呢?
出堆
假如,我将树的根节点出堆,那么根节点不就空缺了么?我应该将第二小的顶替上去。怎么顶替上去呢?一切的一切还是那句话父节点的权值不大于儿子的权值(小顶堆)。
如果仅仅是删除,那么一个堆就会变成两个堆了,问题变复杂了。
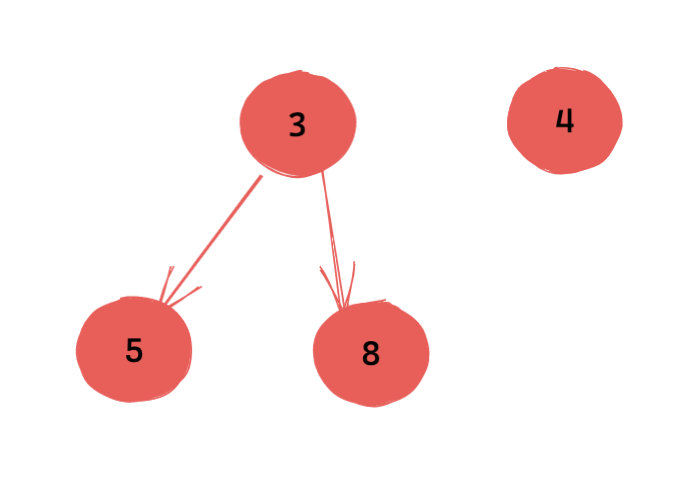
(上图出堆之后会生成两个新的堆)
一个常见的操作是,把根结点和最后一个结点交换。但是新的根结点可能不满足 父节点的权值不大于儿子的权值(小顶堆)。
如下图,我们将根节点的 2 和尾部的数字进行交换后,这个时候是不满足堆性质的。
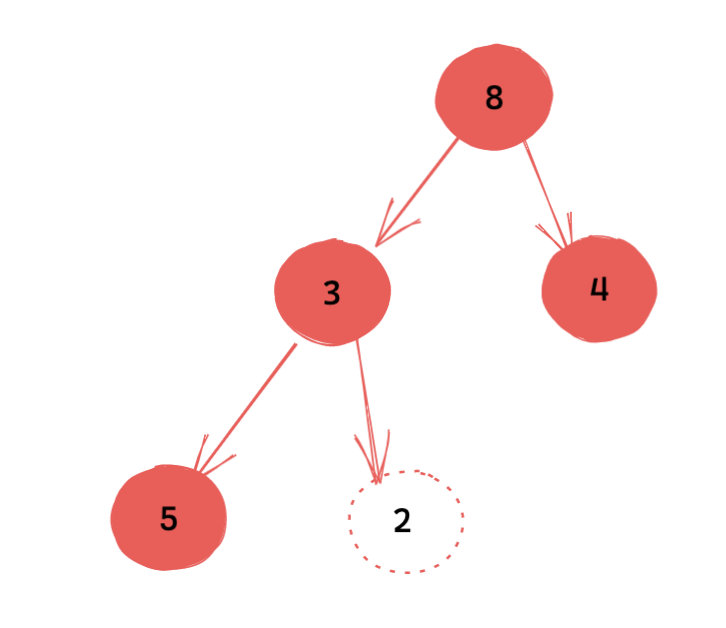
这个时候,其实只需要将新的根节点下沉到正确位置即可。这里的正确位置,指的还是那句话父节点的权值不大于儿子的权值(小顶堆)。如果不满足这一点,我们就继续下沉,直到满足。
我们知道根节点往下下沉的过程,其实有两个方向可供选择,是下沉到左子节点?还是下沉到右子节点?以小顶堆来说,答案应该是下沉到较小的子节点处,否则会错失正确答案。以上面的堆为例,如果下沉到右子节点 4,那么就无法得到正确的堆顶 3。因此我们需要下沉到左子节点。
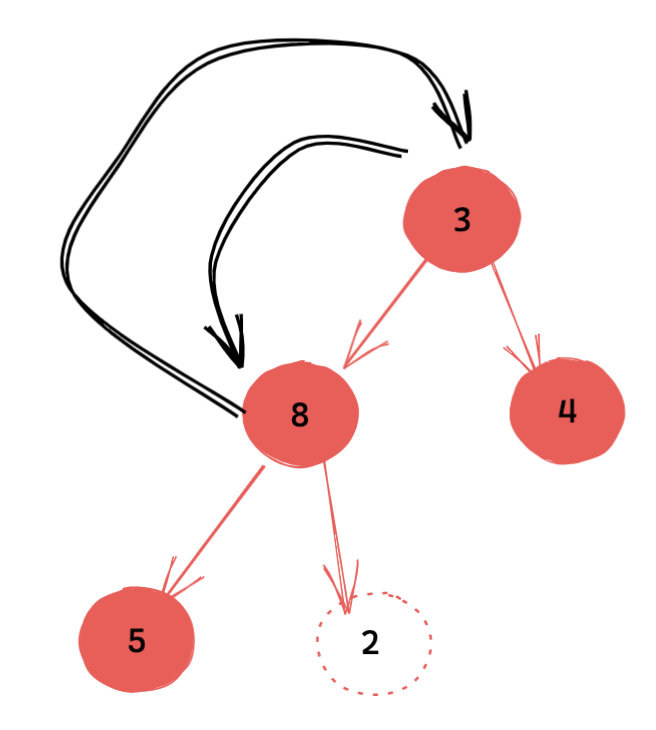
下沉到如图位置,还是不满足 父节点的权值不大于儿子的权值(小顶堆),于是我们继续执行同样的操作。
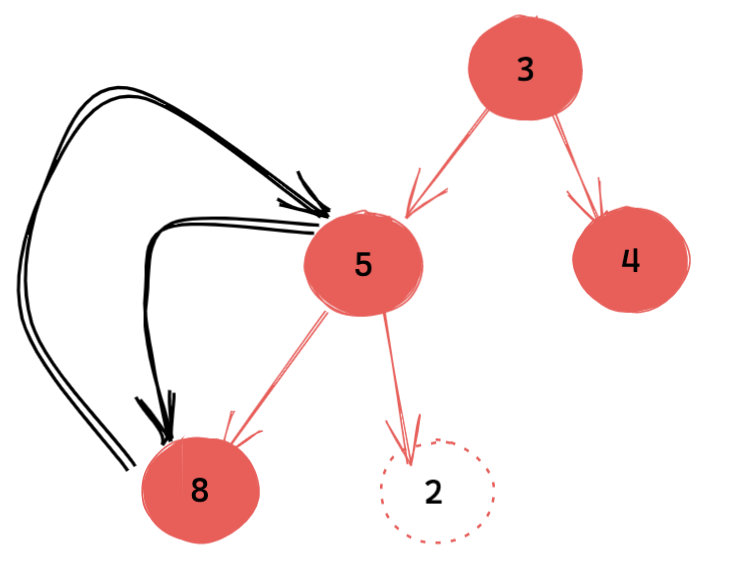
有的同学可能有疑问。弹出根节点前堆满足堆的性质,但是弹出之后经过你上面讲的下沉操作,一定还满足么?
答案是肯定的。这个也不难理解。由于最后的叶子节点被提到了根节点,它其实最终在哪是不确定的,但是经过上面的操作,我们可以看出:
- 其下沉路径上的节点一定都满足堆的性质。
- 不在下沉路径上的节点都保持了堆之前的相对关系,因此也满足堆的性质。
因此弹出根节点后,经过上面的下沉操作一定仍然满足堆的性质。
时间复杂度方面可以证明,下沉和树的高度成正相关,因此时间复杂度为 $O(h)$,其中 h 为树高。而由于二叉堆是一颗完全二叉树,因此树高大约是 $logN$,其中 N 为树中的节点个数。
入堆
入堆和出堆类似。我们可以直接往树的最后插入一个节点。和上面类似,这样的操作同样可能会破坏堆的性质。
之所以这么做的其中一个原因是时间复杂度更低,因为我们是用数组进行模拟的,而在数组尾部添加元素的时间复杂度为 $O(1)$。
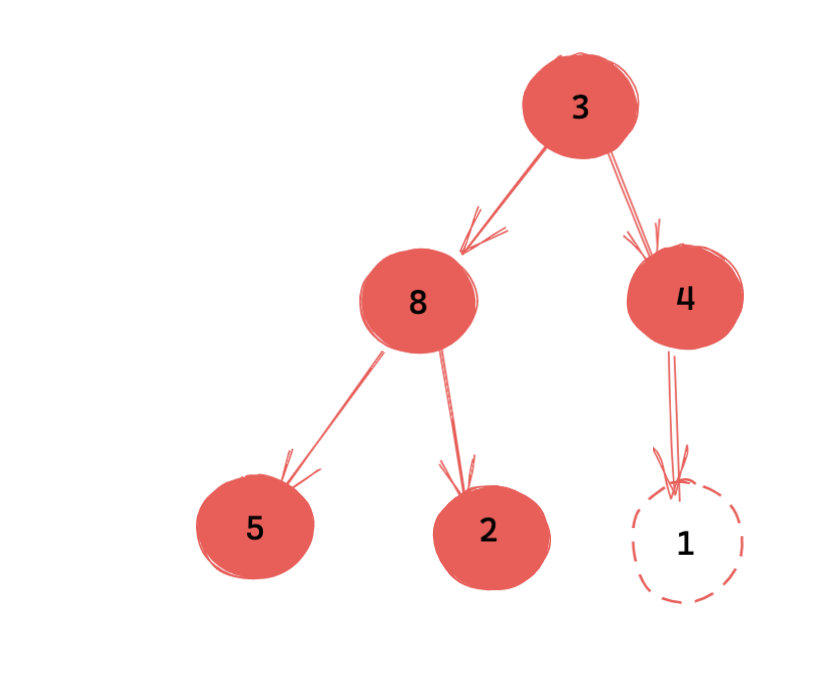
这次我们发现,不满足堆的节点目前是刚刚被插入节点的尾部节点,因此不能进行下沉操作了。这一次我们需要执行上浮操作。
叶子节点是只能上浮的(根节点只能下沉,其他节点既可以下沉,又可以上浮)
和上面基本类似,如果不满足堆的性质,我们将其和父节点交换(上浮),继续这个过程,直到满足堆的性质。
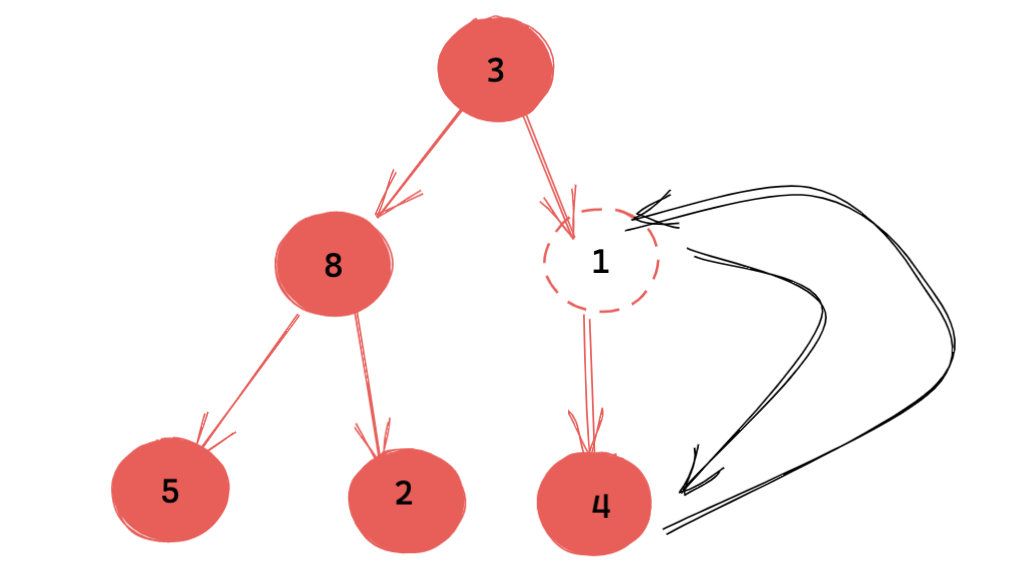
(第一次上浮,仍然不满足堆特性,继续上浮)
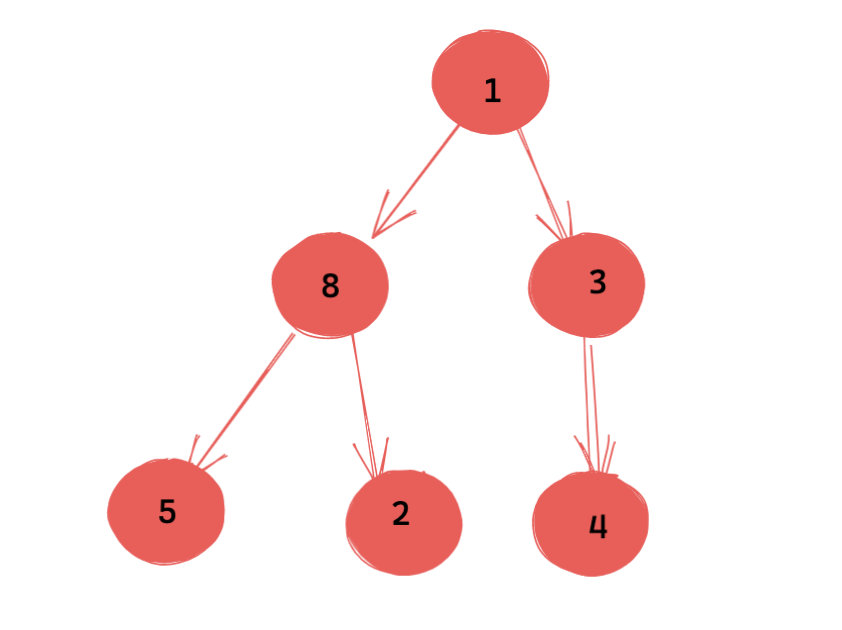
(满足了堆特性,上浮过程完毕)
经过这样的操作,其还是一个满足堆性质的堆。证明过程和上面类似,不再赘述。
需要注意的是,由于上浮只需要拿当前节点和父节点进行比对就可以了, 由于省去了判断左右子节点哪个更小的过程,因此更加简单。
实现
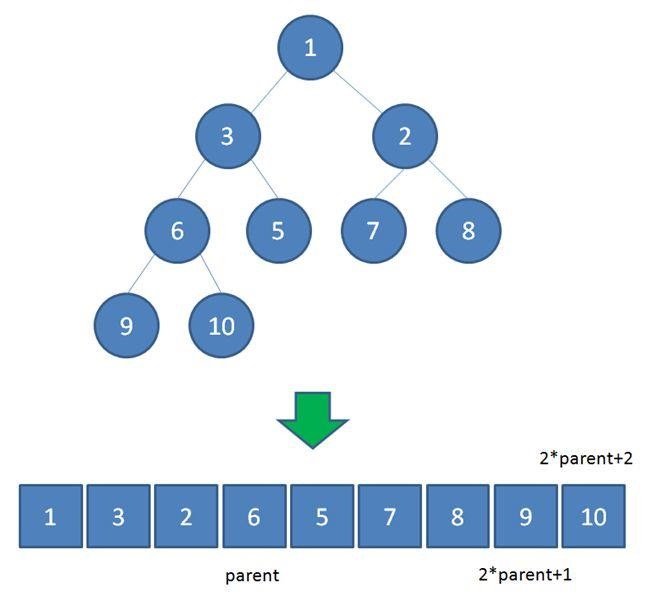
对于完全二叉树来说使用数组实现非常方便。因为:
- 如果节点在数组中的下标为 i,那么其左子节点下标为 $2 \times i$,右节点为 $2 \times i$+1。
- 如果节点在数组中的下标为 i,那么父节点下标为 i//2(地板除)。
当然这要求你的数组从 1 开始存储数据。如果不是,上面的公式其实微调一下也可以达到同样的效果。不过这是一种业界习惯,我们还是和业界保持一致比较好。从 1 开始存储的另外一个好处是,我们可以将索引为 0 的位置空出来存储诸如堆大小的信息,这是一些大学教材里的做法,大家作为了解即可。
如图所示是一个完全二叉树和树的数组表示法。
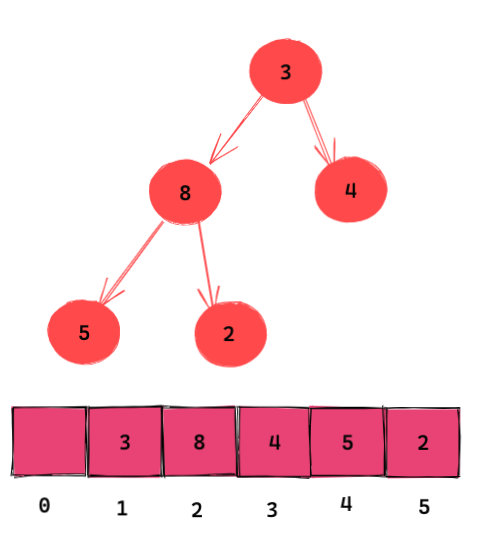
(注意数组索引的对应关系)
形象点来看,我们可以可以画出如下的对应关系图:
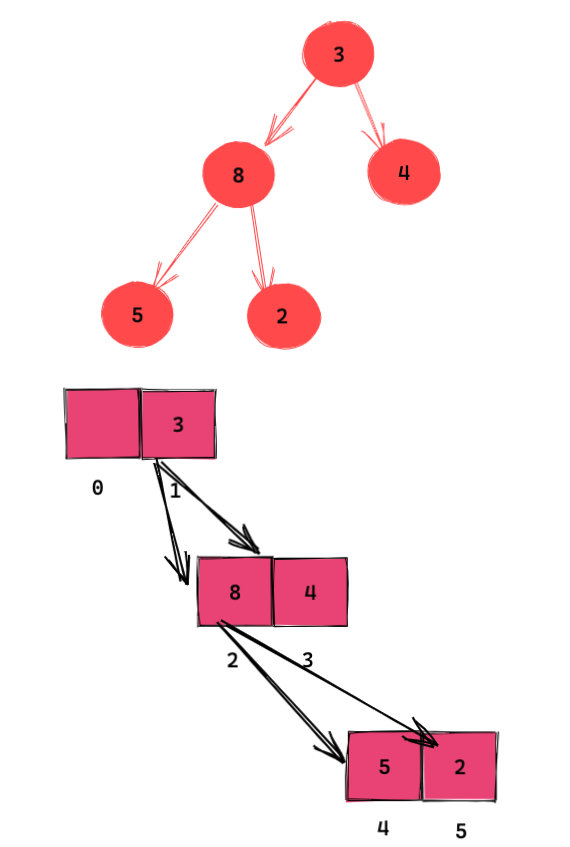
这样一来,是不是和上面的树差不多一致了?有没有容易理解一点呢?
上面已经讲了上浮和下沉的过程。刚才也讲了父子节点坐标的关系。那么代码就呼之欲出了。我们来下最核心的上浮和下沉的代码实现吧。
伪代码:
1 | // x 是要上浮的元素,从树的底部开始上浮 |
这里 Java 语言为例,讲述一下代码的编写。其他语言的二叉堆实现可以去我的刷题插件 leetcode-cheatsheet 中获取。插件的获取方式在公众号力扣加加里,回复插件即可。
1 | import java.util.Arrays; |
小结
堆的实现有很多。比如基于链表的跳表,基于数组的二叉堆和基于红黑树的实现等。这里我们详细地讲述了二叉堆的实现,不仅是其实现简单,而且其在很多情况下表现都不错,推荐大家重点掌握二叉堆实现。
对于二叉堆的实现,核心点就一点,那就是始终维护堆的性质不变,具体是什么性质呢?那就是 父节点的权值不大于儿子的权值(小顶堆)。为了达到这个目的,我们需要在入堆和出堆的时候,使用上浮和下沉操作,并恰当地完成元素交换。具体来说就是上浮过程和比它大的父节点进行交换,下沉过程和两个子节点中较小的进行交换,当然前提是它有子节点且子节点比它小。
关于堆化我们并没有做详细分析。不过如果你理解了本文的入堆操作,这其实很容易。因此堆化本身就是一个不断入堆的过程,只不过将时间上的离散的操作变成了一次性操作而已。
预告
本文预计分两个部分发布。这是第一部分,后面的内容更加干货,分别是三个技巧和四大应用。
- 三个技巧
- 多路归并
- 固定堆
- 事后小诸葛
- 四大应用
- topK
- 带权最短距离
- 因子分解
- 堆排序
这两个主题是专门教你怎么解题的。掌握了它,力扣中的大多数堆的题目都不在话下(当然我指的仅仅是题目中涉及到堆的部分)。
大家对此有何看法,欢迎给我留言,我有时间都会一一查看回答。更多算法套路可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。目前已经 37K star 啦。大家也可以关注我的公众号《力扣加加》带你啃下算法这块硬骨头。
