
最近有粉丝和我交流面试遇到的算法题。其中有一道题比较有意思,分享给大家。
ta 说自己面试了一家某大型区块链的公司的前端岗位,被问到了一道算法题。这道题也是一个非常常见的题目了,力扣中也有原题 110. 平衡二叉树,难度为简单。
不过面试官做了一点点小的扩展,难度瞬间升级了。我们来看下面试官做了什么扩展。
题目
题目是《判断一棵树是否为平衡二叉树》,所谓平衡二叉树指的是二叉树中所有节点的左右子树的深度之差不超过 1。输入参数是二叉树的根节点 root,输出是一个 bool 值。
代码会被以如下的方式调用:
1 | console.log(isBalance([3, 9, 2, null, null, 5, 5])); |
思路
求解的思路就是围绕着二叉树的定义来进行即可。
对于二叉树中的每一个节点都:
- 分别计算左右子树的高度,如果高度差大于 1,直接返回 false
- 否则继续递归调用左右子节点,如果左右子节点全部都是平衡二叉树,那么返回 true。否则返回 false
可以看出我们的算法就是死扣定义。
计算节点深度比较容易,既可以使用前序遍历 + 参考扩展的方式,也可使用后序遍历的方式,这里我用的是前序遍历 + 参数扩展。
对此不熟悉的强烈建议看一下这篇文章 几乎刷完了力扣所有的树题,我发现了这些东西。。。
于是你可以写出如下的代码。
1 | function getDepth(root, d = 0) { |
不难发现,这道题的结果和节点(TreeNode) 的 val 没有任何关系,val 是多少完全不影响结果。
这就完了么?
可以仔细观察题目给的使用示例,会发现题目给的是 nodes 数组,并不是二叉树的根节点 root。
因此我们需要先构建二叉树。 构建二叉树本质上是一个反序列的过程。要想知道如何反序列化,肯定要先知道序列化。
而二叉树序列的方法有很多啊?题目给的是哪种呢?这需要你和面试官沟通。很有可能面试官在等着你问他呢!!!
反序列化
我们先来看下什么是序列化,以下定义来自维基百科:
序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始对象相同语义的副本。对于许多对象,像是使用大量引用的复杂对象,这种序列化重建的过程并不容易。面向对象中的对象序列化,并不概括之前原始对象所关系的函数。这种过程也称为对象编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组、deserialization、unmarshalling)。
可见,序列化和反序列化在计算机科学中的应用还是非常广泛的。就拿 LeetCode 平台来说,其允许用户输入形如:
1 | [1,2,3,null,null,4,5] |
这样的数据结构来描述一颗树:
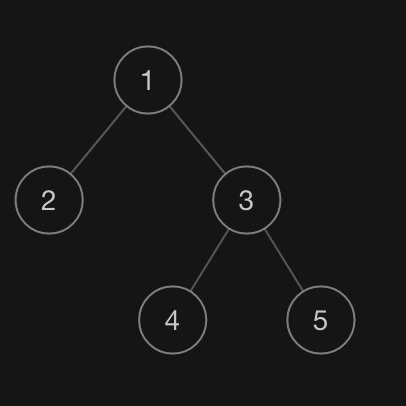
([1,2,3,null,null,4,5] 对应的二叉树)
其实序列化和反序列化只是一个概念,不是一种具体的算法,而是很多的算法。并且针对不同的数据结构,算法也会不一样。
前置知识
阅读本文之前,需要你对树的遍历以及 BFS 和 DFS 比较熟悉。如果你还不熟悉,推荐阅读一下相关文章之后再来看。或者我这边也写了一个总结性的文章二叉树的遍历,你也可以看看。
前言
我们知道:二叉树的深度优先遍历,根据访问根节点的顺序不同,可以将其分为前序遍历,中序遍历, 后序遍历。即如果先访问根节点就是前序遍历,最后访问根节点就是后序遍历,其它则是中序遍历。而左右节点的相对顺序是不会变的,一定是先左后右。
当然也可以设定为先右后左。
并且知道了三种遍历结果中的任意两种即可还原出原有的树结构。这不就是序列化和反序列化么?如果对这个比较陌生的同学建议看看我之前写的《构造二叉树系列》
有了这样一个前提之后算法就自然而然了。即先对二叉树进行两次不同的遍历,不妨假设按照前序和中序进行两次遍历。然后将两次遍历结果序列化,比如将两次遍历结果以逗号“,” join 成一个字符串。 之后将字符串反序列即可,比如将其以逗号“,” split 成一个数组。
序列化:
1 | class Solution: |
反序列化:
这里我直接用了力扣 105. 从前序与中序遍历序列构造二叉树 的解法,一行代码都不改。
1 | class Solution: |
实际上这个算法是不一定成立的,原因在于树的节点可能存在重复元素。也就是说我前面说的知道了三种遍历结果中的任意两种即可还原出原有的树结构是不对的,严格来说应该是如果树中不存在重复的元素,那么知道了三种遍历结果中的任意两种即可还原出原有的树结构。
聪明的你应该发现了,上面我的代码用了 i = inorder.index(root.val),如果存在重复元素,那么得到的索引 i 就可能不是准确的。但是,如果题目限定了没有重复元素则可以用这种算法。但是现实中不出现重复元素不太现实,因此需要考虑其他方法。那究竟是什么样的方法呢?
答案是记录空节点。接下来进入正题。
DFS
序列化
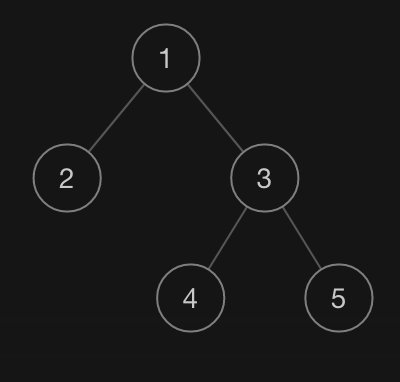
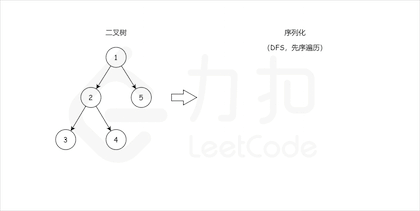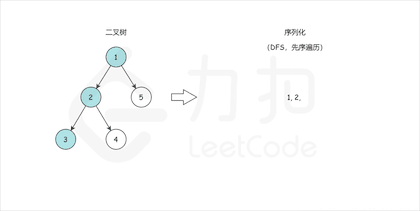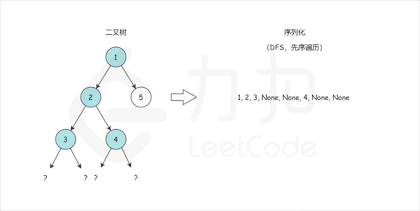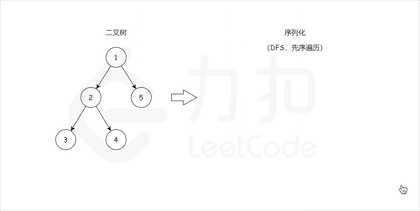
我们来模仿一下力扣的记法。 比如:[1,2,3,null,null,4,5](本质上是 BFS 层次遍历),对应的树如下:
选择这种记法,而不是 DFS 的记法的原因是看起来比较直观。并不代表我们这里是要讲 BFS 的序列化和反序列化。
序列化的代码非常简单, 我们只需要在普通的遍历基础上,增加对空节点的输出即可(普通的遍历是不处理空节点的)。
比如我们都树进行一次前序遍历的同时增加空节点的处理。选择前序遍历的原因是容易知道根节点的位置,并且代码好写,不信你可以试试。
因此序列化就仅仅是普通的 DFS 而已,直接给大家看看代码。
Python 代码:
1 | class Codec: |
Java 代码:
1 | public class Codec { |
[1,2,3,null,null,4,5] 会被处理为1,2,#,#,3,4,#,#,5,#,#
我们先看一个短视频:
(动画来自力扣)
反序列化
反序列化的第一步就是将其展开。以上面的例子来说,则会变成数组:[1,2,#,#,3,4,#,#,5,#,#],然后我们同样执行一次前序遍历,每次处理一个元素,重建即可。由于我们采用的前序遍历,因此第一个是根元素,下一个是其左子节点,下下一个是其右子节点。
Python 代码:
1 | def deserialize_dfs(self, nodes): |
Java 代码:
1 | public TreeNode deserialize_dfs(List<String> l) { |
复杂度分析
- 时间复杂度:每个节点都会被处理一次,因此时间复杂度为 $O(N)$,其中 $N$ 为节点的总数。
- 空间复杂度:空间复杂度取决于栈深度,因此空间复杂度为 $O(h)$,其中 $h$ 为树的深度。
BFS
序列化
实际上我们也可以使用 BFS 的方式来表示一棵树。在这一点上其实就和力扣的记法是一致的了。
我们知道层次遍历的时候实际上是有层次的。只不过有的题目需要你记录每一个节点的层次信息,有些则不需要。
这其实就是一个朴实无华的 BFS,唯一不同则是增加了空节点。
Python 代码:
1 |
|
反序列化
如图有这样一棵树:
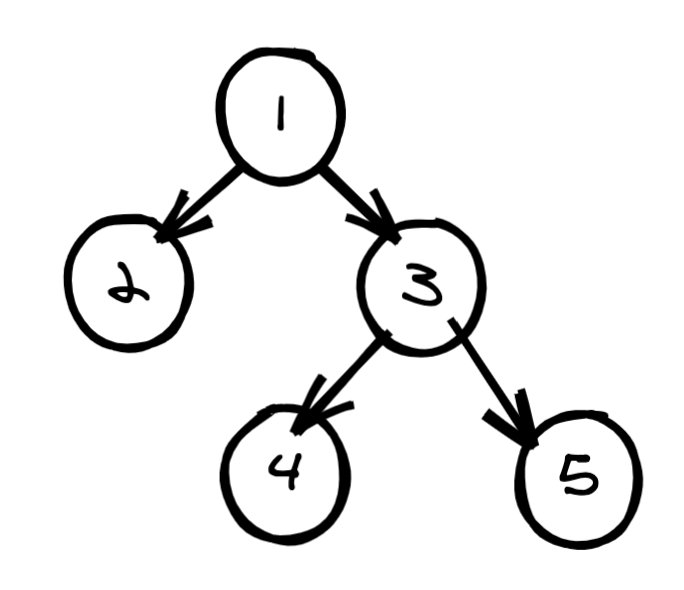
那么其层次遍历为 [1,2,3,#,#, 4, 5]。我们根据此层次遍历的结果来看下如何还原二叉树,如下是我画的一个示意图:
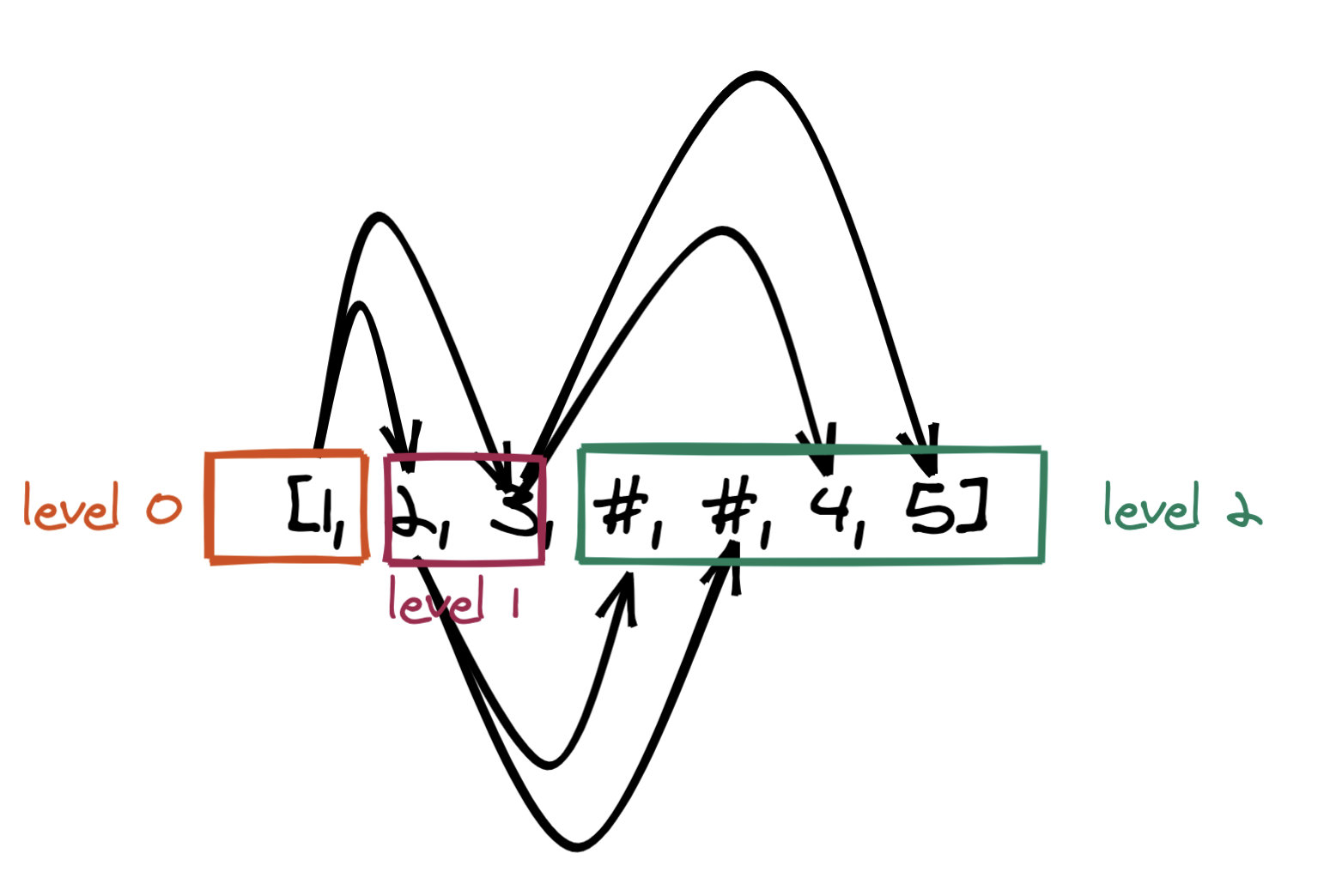
动画演示:

容易看出:
- level x 的节点一定指向 level x + 1 的节点,如何找到 level + 1 呢? 这很容易通过层次遍历来做到。
- 对于给的的 level x,从左到右依次对应 level x + 1 的节点,即第 1 个节点的左右子节点对应下一层的第 1 个和第 2 个节点,第 2 个节点的左右子节点对应下一层的第 3 个和第 4 个节点。。。
- 接上,其实如果你仔细观察的话,实际上 level x 和 level x + 1 的判断是无需特别判断的。我们可以把思路逆转过来:
即第 1 个节点的左右子节点对应第 1 个和第 2 个节点,第 2 个节点的左右子节点对应第 3 个和第 4 个节点。。。(注意,没了下一层三个字)
因此我们的思路也是同样的 BFS,并依次连接左右节点。
Python 代码:
1 | def deserialize(self, data: str): |
复杂度分析
- 时间复杂度:每个节点都会被处理一次,因此时间复杂度为 $O(N)$,其中 $N$ 为节点的总数。
- 空间复杂度:$O(N)$,其中 $N$ 为节点的总数。
这样就结束了吗?
有了上面的序列化的知识。
我们就可以问面试官是哪种序列化的手段。 并针对性选择反序列化方案构造出二叉树。最后再使用本文开头的方法解决即可。
以为这里就结束了吗?
并没有!面试官让他说出自己的复杂度。
读到这里,不妨自己暂停一下,思考这个解法的复杂度是多少?
1
2
3
4
5
ok,我们来揭秘。
时间复杂度是 $O(n) + O(n^2)$,其中 $O(n)$ 是生成树的时间,$O(n^2)$ 是判断是否是平衡二叉树的时间。
为什么判断平衡二叉树的时间复杂度是 $O(n^2)$? 这是因为我们对每一个节点都计算其深度,因此总的时间为所有节点深度之和,最差情况是退化到链表的情况,此时的高度之和为 $1 + 2 + … n$ ,根据等差数列求和公式可知,时间复杂度是 $O(n^2)$。
空间复杂度很明显是 $O(n)$。这其中包括了构建二叉树的 n 以及递归栈的开销。
面试官又追问:可以优化么?
读到这里,不妨自己暂停一下,思考这个解法的复杂度是多少?
1
2
3
4
5
ok,我们来揭秘。
优化的手段有两种。第一种是:
- 空间换时间。将 getDepth 函数的返回值记录下来,确保多次执行 getDepth 且参数相同的情况不会重复执行。这样时间复杂度可以降低到 $O(n)$
- 第二种方法和上面的方法是类似的,其本质是记忆化递归(和动态规划类似)。
我在上一篇文章 读者:西法,记忆化递归究竟怎么改成动态规划啊? 详细讲述了记忆化递归和动态规划的互相转换。如果你看了的话,会发现这里就是记忆化递归。
第一种方法代码比较简单,就不写了。这里给一下第二种方法的代码。
定义函数 getDepth(root) 返回 root 的深度。 需要注意的是,如果子节点不平衡,直接返回 -1。 这样上面的两个函数功能(getDepth 和 isBalance)就可以放到一个函数中执行了。
1 | class Solution: |
总结
虽然这道面试题目是一个常见的常规题。不过参数改了一下,瞬间难度就上来了。如果面试官没有直接给你说 nodes 是怎么序列化来的,他可能是故意的。二叉树序列的方法有很多啊?题目给的是哪种呢?这需要你和面试官沟通。很有可能面试官在等着你问他呢!!! 这正是这道题的难点所在。
构造二叉树本质就是一个二叉树反序列的过程。 而如何反序列化需要结合序列化算法。
序列化方法根据是否存储空节点可以分为:存储空节点和不存储空节点。
存储空节点会造成空间的浪费,不存储空节点会造成无法唯一确定一个包含重复值的树。
而关于序列化,本文主要讲述的是二叉树的序列化和反序列化。看完本文之后,你就可以放心大胆地去 AC 以下两道题:
另外仅仅是暴力做出来还不够,大家要对自己提出更高的要求。
最起码你要会分析自己的算法,常用的就是复杂度分析。进一步如果你可以对算法进行优化会很加分。比如这里我就通过两种优化方法将时间优化到了 $O(n)$。