
大家好,我是 lucifer。今天给大家分享 Git 中的算法。
这是本系列的第二篇 - 《Git 中的最近公共祖先》,第一篇在 这里
git merge-base
git merge-base A B 可以查找 A 提交和 B 提交的最近公共祖先提交。而由于 分支和标签在 Git 中仅仅是提交的别名,因此 A 和 B 也可以是分支或者标签。
1 |
|
如上图的 Git 提交情况,那么 git merge-base A B 会直接返回提交 1 的哈希值。
更多关于 merge-base的用法细节可以参考 官方文档
如何查找公共祖先呢?
我们知道 git 每次提交,实际上都是新建了一个提交对象,里面记录一些元信息。比如:
- 提交人
- 提交时间
- 哈希
- 上一次提交的引用
- 。
而上一次提交的引用导致了 git 提交是一个链表结构。而 git 支持创建分支,并基于分支进行开发,因此 git 提交本质上是有向无环图结构。
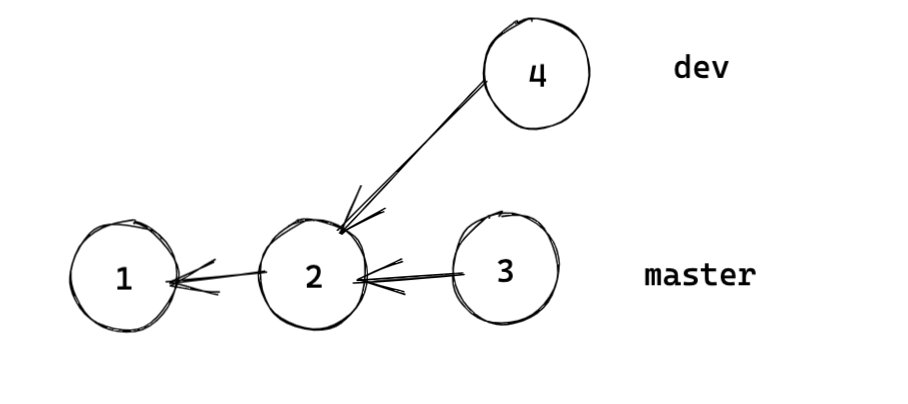
如上图,我们基于提交 2 创建了新分支 dev,dev 上开发后我们可以将其合并到主分支 master。
而当我们执行合并操作的时候,git 会先使用 merge-base 算法计算最近公共祖先。
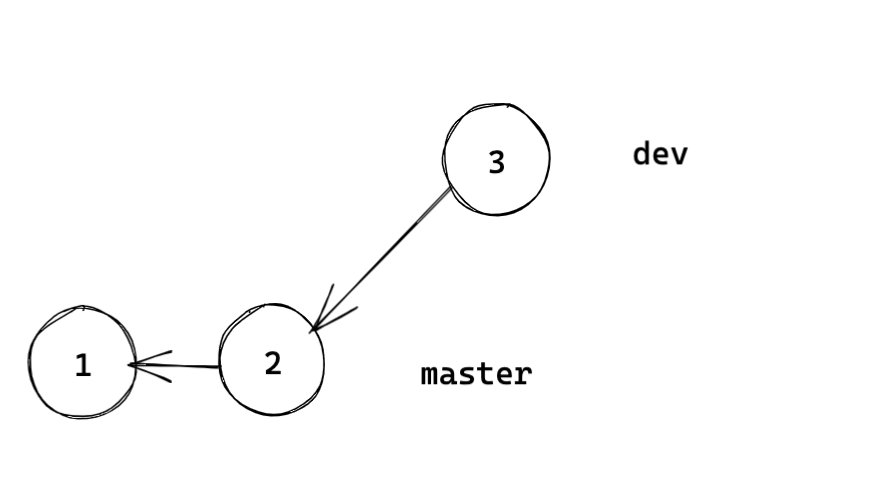
如果最近公共祖先是被 merge 的 commit, 则可执行 fast-forward。如下图,我们将 dev 合并到 master 就可以 fast-forward,就好像没有创建过 dev 分支一样。
最后举一个更复杂的例子。如下图,我们在提交 3 上执行 git merge HEAD 提交 6。会发生什么?
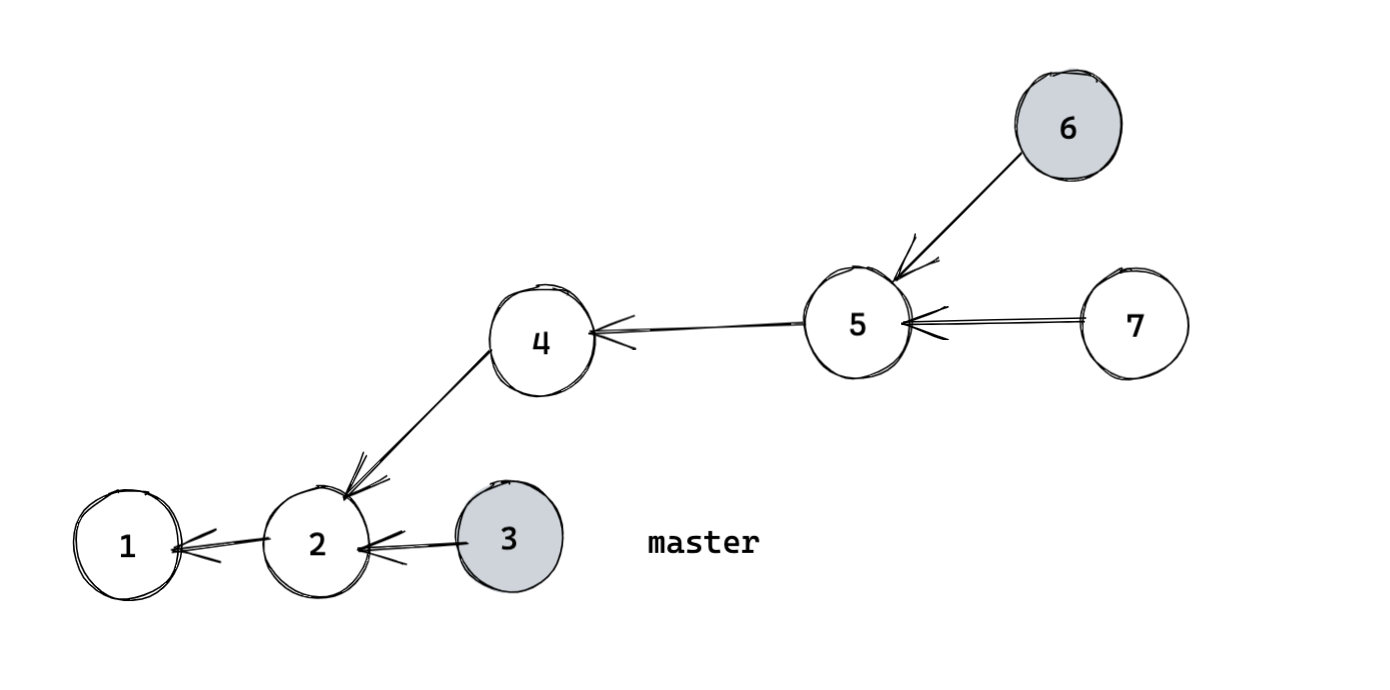
答案是会找到提交 2。那怎么找到 2 呢?
如果从提交 6 出发不断找父节点,找到 1,并将其放到哈希表中。接下来再从提交 3 出发同样不断找父节点,如果父节点在哈希表中存在,那么我们就找到了公共祖先,由于是找到的第一个公共祖先,因此其是最近公共祖先,直接返回即可。
力扣中刚好有一个题目,我们来看下。
力扣真题
题目地址 (236. 二叉树的最近公共祖先)
https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/
题目描述
1 | 给定一个二叉树,找到该树中两个指定节点的最近公共祖先。 |
前置知识
- 二叉树
- 树的遍历
- 哈希表
思路
这道题是给你一个二叉树,让你从二叉树的根出发。
这和 Git 是不一样的,Git 中我们需要从两个提交节点出发往父节点找。
那是不是意味着上面方法不可以套用了?
也不是。我们可以在遍历二叉树的时候维护父子关系,然后问题就转化为了前面的问题。
代码
- 语言支持:Java
Java Code:
1 |
|
复杂度分析
令 n 为链表长度。
- 时间复杂度:$O(n)$
- 空间复杂度:$O(n)$
优化
实际上该算法效率并不高。如果我们仓库提交很多,也就是 N 非常大,也是会慢的。
有没有优化的可能?
当然可以。而且优化的角度有很多。
这不,这位同学就想到了预处理。
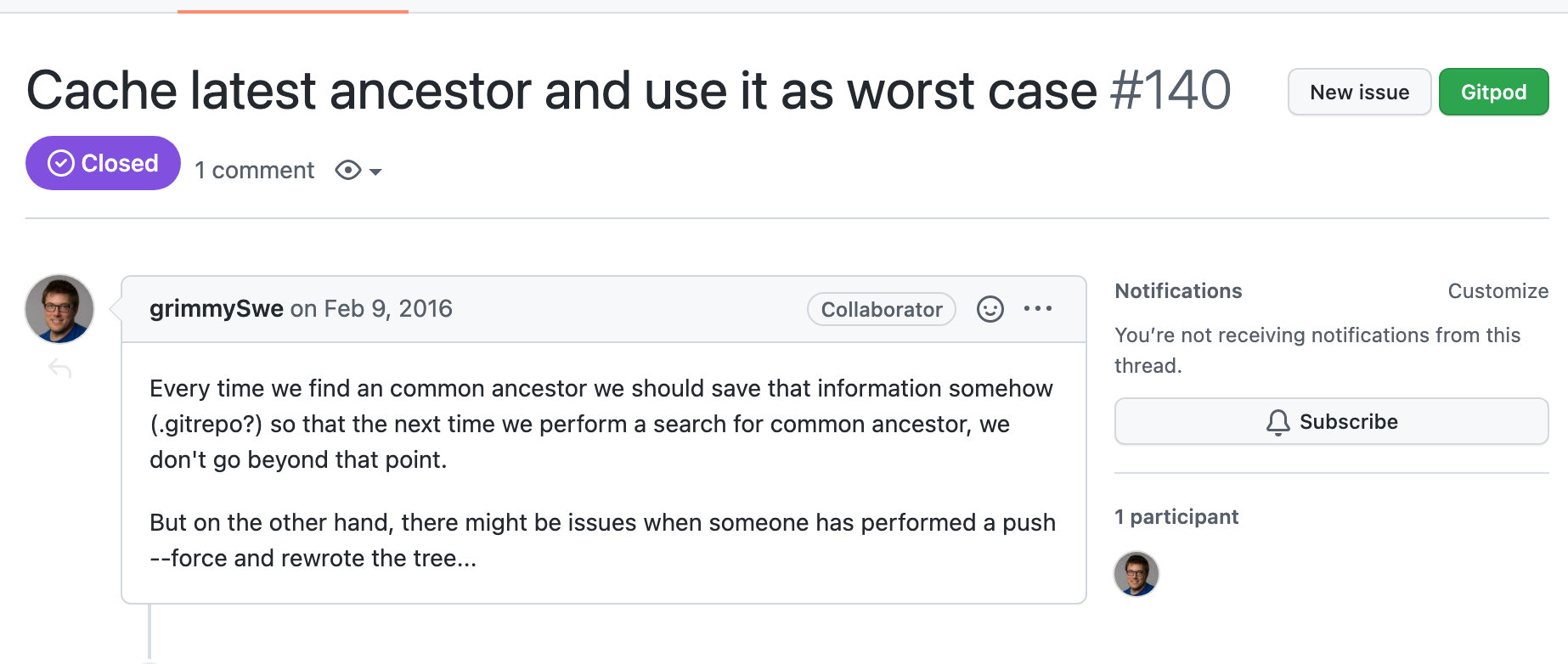
链接在这里。即第一次维护好了节点信息,将其存到文件里,那么以后执行 merge-base,就不需要对已经处理过的节点进行遍历了。理论上,不管 merge-base 多少次,我们都仅遍历一次节点。
真的这么理想么?
很可惜不是的。比如我执行了 rebase ,reset 等操作改变了节点怎么处理?这里的细节很多,我就不在这里展开了。感兴趣的可以加入我的力扣群讨论。
总结
git merge-base 本质上就是一个寻找最近公共祖先的算法。
而这个算法最朴素的就是先从一个节点使用哈希表预处理,然后从另外一个节点开始遍历,找到的第一个在哈希表中出现的节点就是最近公共祖先。
这个算法也有优化空间,而优化后又需要考虑各种边界条件,即缓存失效问题。
以上就是本文的全部内容了。大家对此有何看法,欢迎给我留言,我有时间都会一一查看回答。更多算法套路可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 40K star 啦。大家也可以关注我的公众号《力扣加加》带你啃下算法这块硬骨头。
关注公众号力扣加加,努力用清晰直白的语言还原解题思路,并且有大量图解,手把手教你识别套路,高效刷题。
